Amazon Dynamo
Nguồn
Dynamo: Amazon’s Highly Available Key-value Store
Các tác giả:
- Giuseppe DeCandia
- Deniz Hastorun
- Madan Jampani
- Gunavardhan Kakulapati
- Avinash Lakshman
- Alex Pilchin
- Swaminathan Sivasubramanian
- Peter Vosshall
- Werner Vogels
Tóm tắt
Độ tin cậy (Reliability) ở quy mô lớn là một trong những thách thức mà chúng tôi gặp phải tại Amazon.com, một trong những tập đoàn thương mại điện tử lớn nhất thế giới; chỉ cần vài giây gián đoạn cũng gây ra hậu quả tài chính to lớn và ảnh hưởng đến lòng tin của người dùng. Nền tảng Amazon.com, nơi cung cấp dịch vụ (service) cho rất nhiều website toàn cầu, được xây dựng trên một hạ tầng bao gồm hàng chục nghìn máy chủ (server) và thành phần mạng được đặt ở rất nhiều trung tâm dữ liệu (data center) trên thế giới. Ở quy mô này, các thành phần nhỏ và lớn có thể liên tục gặp sự cố và cách để quản lý trạng thái liên tục khi đối mặt với những lỗi này giúp thúc đẩy độ tin cậy và tính mở rộng (scalability) của hệ thống phần mềm.
Bài báo này giới thiệu thiết kế và cài đặt của Dynamo, một hệ thống lưu trữ khóa-giá trị (key-value) có tính khả dụng cao (highly available) được sử dụng bởi một số hệ thống quan trọng của Amazon để cung cấp một trải nghiệm không gián đoạn cho người dùng. Để đạt được mục tiêu này, Dynamo hi sinh tính nhất quán (consistency) trong một số trường hợp cụ thể. Dynamo còn sử dụng nhiều kỹ thuật như phiên bản hóa (versioning) và giải quyết xung đột (conflict resolution) với sự giúp sức của tầng ứng dụng theo cách cung cấp một giao diện mới mẻ cho nhà phát triển.
1. Giới thiệu
Amazon vận hành một nền tảng thương mại điện tử toàn cầu phục vụ hàng chục triệu khách hàng trong giờ cao điểm với hàng chục nghìn server ở nhiều data center trên thế giới. Có nhiều yêu cầu hoạt động nghiêm ngặt trên nền tảng Amazon về hiệu suất, độ tin cậy và độ hiệu quả. Độ tin cậy là một trong các yêu cầu quan trọng nhất vì một vài giây gián đoạn có thể gây ra hậu quả tài chính to lớn và ảnh hưởng đến lòng tin của người dùng. Thêm nữa, để đáp ứng nhu cầu tăng trưởng liên tục, nền tảng cần có tính mở rộng cao để có thể dễ dàng mở rộng hệ thống khi cần thiết.
Một trong những bài học mà tổ chức của chúng tôi đã học được khi vận hành nền tảng của Amazon là độ tin cậy và tính mở rộng của một hệ thống phụ thuộc vào cách trạng thái ứng dụng được quản lý. Amazon sử dụng một kiến trúc hướng service có tính phi tập trung cao (highly decentralized), liên kết lỏng lẻo (loosely coupled), bao gồm hàng trăm service. Trong môi trường này, sẽ có nhu cầu đặc biệt về các công nghệ lưu trữ có tính khả dụng cao. Ví dụ, khách hàng có thể xem và thêm các mặt hàng vào giỏ hàng của mình ngay cả khi ổ đĩa bị lỗi, các tuyến mạng bị lỗi hoặc các data center bị tàn phá bởi thiên tai. Do đó, service chịu trách nhiệm quản lý giỏ hàng yêu cầu rằng nó luôn có thể ghi và đọc từ data store của mình và data của nó cần phải khả dụng (available) trên nhiều data center.
Xử lý vấn đề trong một hạ tầng gồm hàng triệu thành phần là việc thường xuyên của chúng tôi; luôn có một lượng nhỏ nhưng đáng kể các server và thành phần mạng có thể bị lỗi ở bất kỳ lúc nào. Như vậy các hệ thống phần mềm của Amazon cần phải được xây dựng theo cách mà chúng xem việc xử lý lỗi như chuyện thường ngày ở huyện mà không ảnh hưởng đến tính khả dụng hoặc hiệu suất.
Để đáp ứng các như cầu về độ tin cậy và tính mở rộng, Amazon đã phát triển nhiều công nghệ lưu trữ, trong đó Amazon Simple Storage Service (cũng đã ra mắt công chúng và được biết đến với cái tên Amazon S3) là nổi tiếng nhất. Bài báo này này trình bày thiết kế và cài đặt Dynamo, một data store phân tán có tính khả dụng và tính mở rộng cao khác, được xây dựng cho nền tảng của Amazon. Dynamo được sử dụng để quản lý trạng thái của các service có nhiều yêu cầu về độ tin cậy vào cùng với việc kiểm soát chặt chẽ những sự cân bằng về tính khả dụng, tính nhất quán, hiệu quả chi phí và hiệu suất. Nền tảng của Amazon có một tập rất đa dạng các ứng dụng với nhiều yêu cầu lưu trữ khác nhau. Một tập các ứng dụng như thế yêu cầu một công nghệ lưu trữ đủ linh hoạt để cho phép các nhà thiết kế ứng dụng cấu hình data store một cách thích hợp, dựa trên những sự cân bằng ở trên để đạt được tính khả dụng cao và đảm bảo hiệu quả với chi phí hợp lý nhất.
Có rất nhiều service trên nền tảng của Amazon mà chỉ cần truy cập bằng khóa chính để lấy dữ liệu. Với nhiều service, như danh sách các nhà bán hàng tốt nhất, giỏ hàng, sở thích khách hàng, quản lý session, thứ hạng bán hàng và danh mục sản phẩm, mô hình chung của việc sử dụng cơ sở dữ liệu quan hệ (relational database) sẽ dẫn đến sự kém hiệu quả và hạn chế quy mô và tính khả dụng. Dynamo cung cấp một giao diện chỉ có khóa chính đơn giản để đáp ứng yêu cầu của các ứng dụng này.
Dynamo sử dụng kết hợp các ký thuật phổ biến để đạt được tính khả dụng và tính mở rộng. Data được phân vùng (partition) và sao chép (replicate) bằng cách sử dụng hàm băm nhất quán (consistent hashing) [10], và tính nhất quán được hỗ trợ bằng cách phiên bản hóa đối tượng (object versioning) [12]. Tính nhất quán giữa các bản sao dữ liệu (replica) trong quá trình cập nhật được duy trì bằng một kỹ thuật kiểu quorum và một giao thức đồng bộ hóa bản sao phi tập trung (decentralized replica synchronization protocol). Dynamo sử dụng một giao thức thành viên và phát hiện lỗi phân tán dựa trên gossip. Dynamo là một hệ thống hoàn toàn phi tập trung với việc quản trị thủ công giảm đến mức tối thiểu. Các node lưu trữ có thể được thêm vào và bớt khỏi Dynamo mà không yêu cầu bất kỳ việc phân vùng và tái phân phối thủ công nào.
Trong năm qua, Dynamo là công nghệ lưu trữ đằng sau một cơ số các service cốt lõi trong nền tảng thương mại điện tử của Amazon. Nó có thể tăng quy mô lên mức cực đại một cách hiệu quả mà không có thời gian chết trong mùa mua sắm. Ví dụ, service quản lý giỏ hàng phục vụ hàng chục triệu yêu cầu đã mang lại hơn 3 triệu lượt thanh toán trong một ngày và service quản lý session đã xử lý hàng trăm nghìn session hoạt động đồng thời.
Đóng góp chính của công việc này cho cộng đồng nghiên cứu là việc đánh giá làm thế nào các kỹ thuật khác nhau có thể được kết hợp để tạo ra một hệ thống có tính khả dụng cao. Nó chứng tỏ rằng một hệ thống lưu trữ eventually-consistent có thể được dùng trong các ứng dụng có nhu cầu. Nó cũng cung cấp cái nhìn sâu sắc về việc điều chỉnh các kỹ thuật này để đáp ứng các nhu cầu của hệ thống thực với rất nhiều yêu cầu về hiệu suất khắt khe.
Bài báo này được trình bày như sau. Phần 2 giới thiệu bối cảnh và Phần 3 trình bày các công việc liên quan. Phần 4 trình bày thiết kế hệ thống và Phần 5 mô tả cài đặt. Phần 6 trình bày chi tiết những kinh nghiệm và hiểu biết của chúng tôi khi vận hành Dynamo trong thực tế và Phần 7 kết luận bài báo. Có một số chỗ trong bài viết này cần thêm một số thông tin hay ho nữa nhưng việc bảo vệ lợi ích kinh doanh của Amazon yêu cầu chúng tôi phải giảm các chi tiết này đi. Vì lý do này, phần về độ trễ trong và giữa các data center trong phần 6, tỉ lệ request tuyệt đối trong phần 6.2, thời gian ngừng hoạt động và khối lượng công việc trong phần 6.3 được cung cấp thông qua các chỉ số tổng hợp thay vì các chi tiết cụ thể.
2. Bối cảnh
Nền tảng thương mại điện tử của Amazon được kết hợp bởi hàng trăm service hoạt động phối hợp với nhau để cung cấp các chức năng khác nhau từ đề xuất, thực hiện đơn hàng đến phát hiện gian lận. Mỗi service được thể hiện thông qua một giao diện được xác định rõ ràng và có thể truy cập qua mạng. Các service này được host trên một hạ tầng bao gồm hàng chục nghìn server được đặt ở nhiều trung tâm dữ liệu trên thế giới. Một số service trong này thì stateless (ví dụ như các service tổng hợp phản hồi từ các service khác), và một số thì stateful (ví dụ như service tạo ra phản hồi bằng cách thực thi các logic nghiệp vụ dựa trên trạng thái được lưu trữ trong persistent store).
Các hệ thống truyền thống lưu trạng thái của chúng trong các database quan hệ. Tuy nhiên, đối với nhiều mô hình sử đụng trạng thái bền vững, database quan hệ không phải là một lựa chọn tốt. Hầu hết các service này chỉ lưu trữ và truy xuất dữ liệu bằng khóa chính và không yêu cầu chức năng quản lý và truy vấn phức tập do database quan hệ cung cấp. Các chức năng dư thừa đòi hỏi phần cứng đắt tiền và nhân viên có tay nghề cao để vận hành, khiến nó trở thành một giải pháp rất kém hiệu quả. Ngoài ra, các công nghệ replicate dữ liệu hiện thời còn hạn chế và thường chọn tính nhất quán hơn là tính khả dụng. Mặc dù đã có nhiều tiến bộ đạt được trong những năm qua, ta vẫn không dễ để mở rộng các database hoặc dùng phân vùng thông minh để cân bằng tải.
Bài báo này mô tả Dynamo, một công nghệ lưu trữ dữ liệu có tính khả dụng cao, giúp giải quyết nhu cầu về lớp service này. Dynamo có giao diện key-value đơn giản, và có tính khả dụng cao với vùng nhất quán rõ ràng, hiệu quả trong việc sử dụng tài nguyên và có thể mở rộng một cách đơn giản để giải quyết sự tăng trưởng về kích thước tập dữ liệu hoặc tốc độ yêu cầu. Mỗi service sử dụng Dynamo đều chạy các phiên bản Dynamo của riêng nó.
2.1. Các yêu cầu và giả định cho hệ thống
Hệ thống lưu trữ cho các kiểu service này có các yêu cầu sau:
Mô hình truy vấn: Các thao tác đọc và ghi đơn giản vào một data item được xác định duy nhất bởi một khóa. Trạng thái được lưu trữ dưới dạng binary object (như blob) được xác định bởi các khóa duy nhất. Không có thao tác nào liên quan đến nhiều bản ghi và không cần có sơ đồ quan hệ. Yêu cầu này dựa trên một nhận xét rằng phần lớn các service của Amazon có thể hoạt động chỉ với mô hình truy vấn này và không cần bất kỳ sơ đồ quan hệ nào. Dynamo nhắm vào các ứng dụng cần lưu các đối tượng có kích thước nhỏ (thường nhỏ hơn 1 MB).
Tính chất ACID: ACID (Atomicity - Tính nguyên tử, Consistency - Tính nhất quán, Isolation - Tính độc lập, Durability - Tính bền vững) là một tập các tính chất được đưa ra để đảm bảo các transaction trong database được thực thi một cách đáng tin cậy. Trong hoàn cảnh của các database, một thao tác logic đơn trên dữ liệu được gọi là một transaction. Kinh nghiệm ở Amazon cho thấy rằng các data store với tính chất ACID thường có tính khả dụng khá tệ. Điều này đã được kiểm nghiệm bởi cả những công trình nghiên cứu và thực tế [5]. Dynamo tập trung vào các ứng dụng vận hành với tính nhất quán ít hơn (chữ "C" trong ACID ấy) nếu điều này hỗ trợ tính khả dụng cao hơn. Dynamo không cung cấp sự đảm bảo tính độc lập (isolation guarantee) và chỉ cho phép cập nhật một khóa duy nhất.
Độ hiệu quả: Hệ thống cần được hoạt động trên một hạ tầng phần cứng thương mại. Trên nền tảng của Amazon, các service có những yêu cầu nghiêm ngặt về độ trễ, thường được đo ở phân vị 99.9 (99.9th percentile) trong hệ thống phân tán. Do quyền truy cập trạng thái đóng một vai trò quan trọng trong hoạt động service nên hệ thống lưu trữ phải có khả năng đáp ứng các SLA nghiêm ngặt như vậy (xem phần 2.2 ở dưới). Các service phải có khả năng định cấu hình Dynamo sao cho chúng luôn đạt được các yêu cầu về độ trễ (latency) và thông lượng (throughput). Đánh đổi nằm ở hiệu suất, hiệu quả chi phí, tính khả dụng và đảm bảo tính bền vững.
Các giả định khác: Dynamo chỉ được sử dụng bởi các service nội bộ của Amazon. Môi trường hoạt động của nó được coi là không thù địch và không có các yêu cầu liên quan đến bảo mật như xác thực và ủy quyền. Hơn nữa, vì mỗi service sử dụng phiên bản Dynamo riêng biệt nên thiết kế ban đầu của nó hướng tới quy mô lên đến hàng trăm máy chủ lưu trữ. Chúng ta sẽ thảo luận về các hạn chế về khả năng mở rộng của Dynamo và các tiện ích mở rộng có thể có liên quan đến khả năng mở rộng trong các phần sau.
2.2. Thỏa thuận mức dịch vụ (Service Level Agreements - SLA)
Để đảm bảo rằng ứng dụng có thể cung cấp các tính năng trong thời gian cho phép, mỗi và mọi thành phần của nền tảng cần phải cung cấp các tính năng của chúng trong thời gian thậm chí còn ngắn hơn. Khách hàng và service sẽ có một thỏa thuận mức dịch vụ (Service Level Agreement - SLA). Đó là một hợp đồng thương lượng chính thức giữa khách hàng và service về một số đăc điểm liên quan đến hệ thống, trong đó nổi bật nhất là phân bổ tỉ lệ request dự kiến của khách hàng cho một API cụ thể và độ trễ service dự kiến dưới những điều kiện đó. Một ví dụ về SLA đơn giản là một service đảm bảo rằng nó sẽ trả về response trong vòng 300ms với 99.9% request khi tải lớn nhất là 500 request trên giây.
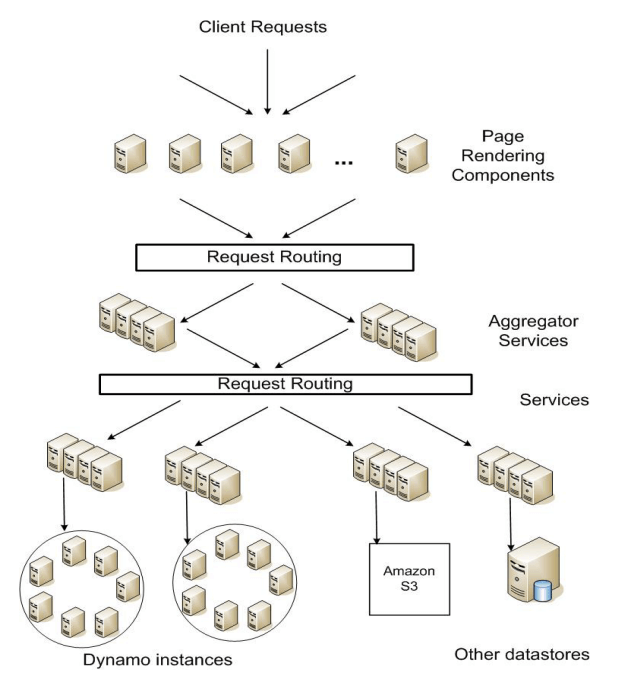
Trên hạ tầng hướng dịch vụ phi tập trung của Amazon, các SLA đóng vai trò rất quan trong. Ví dụ, một request đến một trong các site thương mại điện tử thường cần công cụ kết xuất (rendering engine) trang phải tạo ra response bằng cách gửi các request nhỏ đến hơn 150 service khác. Các service này thường phụ thuộc vào một số thành phần khác, thường là các service khác nữa, và cũng không có gì lạ khi phải gọi request qua nhiều service khác nhau. Để đảm bảo rằng rendering engine của trang có thể duy trì một giới hạn phân phối trang rõ ràng, mỗi service trong chuỗi các service này phải tuân theo hợp đồng hiệu suất của nó.
Hình 1 ở trên cho ta một cái nhìn toàn cảnh về kiến trúc của nền tảng Amazon, nơi nội dung web động được tạo ra bằng các thành phần kết xuất, các thành phần này lại gọi nhiều service khác nhau nữa. Một service có thể dùng nhiều data store khác nhau để quản lý trạng thái của chính nó, và các data store này chỉ có thể được truy cập trong ranh giới service của service đó. Một số service hoạt động như một bộ tổng hợp (aggregator) bằng cách sử dụng một số service khác để tạo ra response tổng hợp. Thông thường, các dịch vụ tổng hợp (aggregator service) đi theo hướng stateless, mặc dù chúng dùng caching rất nhiều.
Một phương pháp phổ biến để tạo một SLA hướng hiệu suất là mô tả nó với các biến thể trung bình (average), trung vị (median) và kì vọng (expected). Ở Amazon, chúng tôi nhận thấy rằng các chỉ số này không phản ánh đầy đủ trong trường hợp mục tiêu là tạo ra một hệ thống nơi tất cả các khách hàng đều có trải nghiệm tốt, hơn là chỉ đa số. Ví dụ, nếu sử dụng các kỹ thuật cá nhân hoá rộng rãi thì các khách hàng lâu dài sẽ yêu cầu xử lý nhiều hơn, điều này sẽ ảnh hưởng đến hiệu suất ở phân khúc cao cấp. Một SLA dưới dạng thời gian response trung bình hoặc trung vị sẽ không giải quyết được vấn đề hiệu suất của phân khúc khách hàng quan trọng này. Để giải quyết vấn đề này, các SLA ở Amazon được thể hiện và đo lường ở phân vị thứ 99.9 của mức phân phối. Lựa chọn 99.9% so với tỉ lệ phần trăm thậm chí còn cao hơn đã được thực hiện dựa trên phân tích chi phí - lợi ích cho thấy rằng chi phí đã tăng đáng kể để cải thiện hiệu suất đến mức đó. Kinh nghiệm với các hệ thống live của Amazon đã chỉ ra rằng cách tiếp cận này mang lại trải nghiệm tổng thể tốt hơn so với những hệ thống đáp ứng SLA được xác định dựa trên các chỉ số trung bình.
Trong bài báo này có nhiều tài liệu tham khảo về phân vị phân phối thứ 99.9 này, điều này phản ánh sự tập trung không ngừng nghỉ của các kỹ sư Amazon vào hiệu suất từ góc độ trải nghiệm của khách hàng. Nhiều bài báo khác báo cáo mức trung bình, nên chúng được đưa vào khi có ý nghĩa cho việc so sánh. Tuy nhiên, nỗ lực tối ưu hoá và kỹ thuật của Amazon không tập trung vào các giá trị trung bình. Một số kỹ thuật, chẳng hạn như lựa chọn cân bằng tải của các write coordinator, hoàn toàn nhằm mục đích kiểm soát hiệu suất ở phân vị thứ 99.9.
Các hệ thống lưu trữ thường đóng vai trò quan trọng trong việc thiết lập SLA của service, đặc biệt nếu logic nghiệp vụ tương đối nhẹ, như trường hợp của nhiều service của Amazon. Quản lý trạng thái sau đó trở thành thành phần chính của SLA của service. Một trong những thứ cần cân nhắc trong thiết kế chính của Dynamo là việc cung cấp cho các service quyền kiểm soát các thuộc tính hệ thống của chúng, như tính bền vững hoặc tính nhất quán, đồng thời cho phép các service tự cân bằng giữa chức năng, hiệu suất và hiệu quả chi phí.
2.3. Các cân nhắc về thiết kế
Các thuật toán replicate dữ liệu được sử dụng trong các hệ thống thương mại thường thực hiện sao chép đồng bộ (synchronous replica coordination) để cung cấp giao diện truy cập dữ liệu nhất quán mạnh (strong consistency). Để đạt được mức độ nhất quán này, các thuật toán như vậy buộc phải đánh đổi tính khả dụng của dữ liệu trong các tính huống lỗi nhất định. Ví dụ, thay vì giải quyết sự không chắc chắn về tính chính xác của response, dữ liệu sẽ từ chối trả về cho đến khi nó chắc chắn đúng. Từ những hệ thống database hỗ trợ replication đầu tiên, người ta biết rằng khi xử lý khả năng xảy ra lỗi mạng, không thể đạt được đồng thời tính nhất quán mạnh và tính khả dụng dữ liệu cao [2, 11], vì các hệ thống và ứng dụng như vậy cần phải biết rằng các đặc tính nào có thể đạt được và đạt được trong các điều kiện nào.
Với các hệ thống dễ xảy ra lỗi server hoặc mạng, có thể tăng tính khả dụng bằng cách sử dụng các kỹ thuật sao chép lạc quan (optimistic replication technique), trong đó các thay đổi được phép truyền tới các replica ở background và những việc đồng thời, không liên quan đến nhau được chấp nhận. Thách thức ở đây là nó có thể dẫn tới những thay đổi xung đột với nhau, chúng cần phải được phát hiện và giải quyết. Quá trình giải quyết xung đột dữ liệu có hai vấn đề: khi nào giải quyết và ai giải quyết. Dynamo được thiết kế để trở thành một data store nhất quán đến cùng (eventual consistency); nghĩa là tất cả các cập nhật đến cuối cùng cũng sẽ đến tất cả các replica.
Một điều quan trọng cần cân nhắc trong thiết kế là quyết định thời điểm thực hiện quy trình giải quyết xung đột trong cập nhât dữ liệu, tức là liệu xung đột có nên được giải quyết trong quá trình đọc hoặc ghi dữ liệu hay không. Nhiều data store truyền thống giải quyết xung đột trong quá trình ghi và giữ cho việc đọc đơn giản hơn [7]. Trong các hệ thống như vậy, việc ghi có thể bị từ chối nếu data store không thể kết nối đến tất cả (hoặc phần lớn) các bản sao tại một thời điểm nhất định. Mặt khác, Dynamo nhắm đến không gian thiết kế của một data store "luôn ghi được" (tức là một cái data store mà việc ghi dữ liệu không bao giờ bị từ chối). Đối với một số service của Amazon, việc từ chối việc ghi dữ liệu của khách có thể dẫn đến trải nghiệm khách hàng kém. Ví dụ, service giỏ hàng phải cho phép khách hàng thêm và xóa các mặt hàng khỏi giỏ hàng của họ ngay cả khi mạng và máy chủ bị lỗi, yêu cầu này buộc chúng tôi phải đẩy sự phức tạp của việc giải quyết xung đột sang các lần đọc để đảm bảo rằng việc ghi không bao giờ bị từ chối.
Lựa chọn thiết kế tiếp theo là ai sẽ thực hiện giải quyết xung đột dữ liệu. Điều này có thể được thực hiện bởi chính ứng dụng hoặc data store. Nếu việc giải quyết xung đột được thực hiện bởi data store thì các lựa chọn của nó sẽ khá hạn chế. Trong các trường hợp như vậy, data store chỉ có thể dùng một số cách đơn giản, như "lần ghi cuối thắng" (last write wins) [22] để giải quyết xung đột cập nhật. Mặt khác, vì ứng dụng nhận thức được lược đồ dữ liệu nên nó có thể quyết định phương pháp giải quyết xung đột phù hợp nhất với trải nghiệm của khách hàng. Ví dụ, ứng dụng quản lý giỏ hàng của khách hàng có thể chọn "hợp nhất" các phiên bản (version) xung đột và trả về một giỏ hàng thống nhất. Bất chấp tính linh hoạt này, một số nhà phát triển ứng dụng có thể không muốn viết cơ chế giải quyết xung đột của riêng họ và chọn đẩy nó xuống data store, do đó, data store sẽ chọn một cách đơn giản như "last write wins".
Một số nguyên tắc khác được áp dụng trong thiết kế là:
- Khả năng mở rộng tăng dần (Incremental scalability): Dynamo nên có khả năng mở rộng quy mô một máy chủ lưu trữ (node) tại một thời điểm, với tác động tối thiểu đến người vận hành hệ thống và chính hệ thống.
- Tính đối xứng (Symmetry): Mọi node trong Dynamo phải có cùng vai trò và chịu trách nhiệm tương tự nhau. Không có node nào có vai trò đặc biệt trong việc xử lý các request của khách hàng. Theo kinh nghiệm của chúng tôi, tính đối xứng giúp đơn giản hóa quá trình vận hành và bảo trì hệ thống.
- Tính phi tập trung (Decentralization): Mở rộng của tính đối xứng, thiết kế nên ưu tiên các kỹ thuật ngang hàng phi tập trung hơn là kiểm soát tập trung. Trước đây, việc kiểm soát tập trung đã dẫn đến tình trạng ngừng hoạt động dịch vụ và mục tiêu là tránh nó xảy ra. Điều này dẫn đến một hệ thống đơn giản hơn, có khả năng mở rộng hơn và khả dụng hơn.
- Tính không đồng nhất (Heterogeneity): Hệ thống cần có khả năng khai thác tính không đồng nhất trong cơ sở hạ tầng mà nó chạy trên đó. Ví dụ, việc phân bổ công việc phải tỷ lệ thuận với khả năng của từng máy chủ. Điều này rất cần thiết trong việc thêm các node mới có sức mạnh tốt hơn mà không cần phải nâng cấp tất cả các máy chủ cùng một lúc.
3. Các công việc liên quan
3.1. Các hệ thống ngang hàng (Peer-to-peer systems)
Có một số hệ thống ngang hàng (peer-to-peer - P2P) đã xem xét vấn đề lưu trữ và phân phối dữ liệu. Thế hệ hệ thống P2P đầu tiên, như Freenet và Gnutella, chủ yếu được sử dụng làm hệ thống chia sẻ file. Đây là những ví dụ về mạng P2P không có cấu trúc trong đó các liên kết lớp phủ giữa các mạng ngang hàng được thiết lập tùy ý. Trong các mạng này, một truy vấn tìm kiếm thường đi khắp mạng để tìm càng nhiều máy chủ ngang hàng chia sẻ dữ liệu càng tốt. Các hệ thống P2P đã phát triển sang thế hệ tiếp theo, trở thành cái được gọi là mạng P2P có cấu trúc. Các mạng này sử dụng giao thức nhất quán toàn cầu để đảm bảo rằng bất kỳ node nào cũng có thể định tuyến truy vấn tìm kiếm đến một số thiết bị ngang hàng có dữ liệu mong muốn một cách hiệu quả. Các hệ thống như Pastry [16] và Chord [20] sử dụng cơ chế định tuyến để đảm bảo rằng các truy vấn có thể được trả lời trong một số bước nhảy giới hạn. Để giảm độ trễ bổ sung do định tuyến nhiều bước tạo ra, một số hệ thống P2P (ví dụ như [14]) sử dụng định tuyến O(1) trong đó mỗi thiết bị ngang hàng duy trì đủ thông tin định tuyến cục bộ để nó có thể định tuyến các yêu cầu (để truy cập một dữ liệu nào đó) tới thiết bị ngang hàng thích hợp trong một số bước nhảy cố định.
Nhiều hệ thống lưu trữ như Oceanstore [9] và PAST [17] được xây dựng dựa trên các lớp phủ định tuyến này. Oceanstore cung cấp dịch vụ lưu trữ liên tục, mang tính giao dịch, toàn cầu, hỗ trợ cập nhật tuần tự trên dữ liệu được replicate rộng rãi. Để cho phép cập nhật đồng thời trong khi tránh được nhiều vấn đề cố hữu với khóa diện rộng, nó sử dụng mô hình cập nhật dựa trên giải quyết xung đột. Việc giải quyết xung đột đã được nói đến trong [21] để giảm số lượng transaction bị hủy bỏ. Oceanstore giải quyết xung đột bằng cách xử lý một loạt các cập nhật, chọn tổng thứ tự (total order) trong số chúng và sau đó áp dụng chúng một cách nguyên tử (atomically) theo thứ tự đó. Nó được xây dựng cho môi trường nơi dữ liệu được sao chép trên cơ sở hạ tầng không đáng tin cậy. Để so sánh, PAST cung cấp một lớp trừu tượng đơn giản trên Pastry cho các object bền vững và không thể thay đổi. Nó giả định rằng ứng dụng có thể xây dựng ngữ nghĩa lưu trữ cần thiết (chẳng hạn như các file có thể thay đổi) trên đó.
3.2. Các database và hệ thống file phân tán
Phân phối dữ liệu hướng tới hiệu suất, tính khả dụng và độ bền đã được nghiên cứu rộng rãi trong cộng đồng hệ thống file và hệ thống database. So với các hệ thống lưu trữ P2P chỉ hỗ trợ các namespace phẳng, các hệ thống file phân tán thường hỗ trợ các namespace phân cấp. Các hệ thống như Ficus [15] và Coda [19] sao chép các file để có tính khả dụng cao nhưng phải đánh đổi bằng tính nhất quán. Xung đột cập nhật thường được quản lý bằng các hàm giải quyết xung đột chuyên biệt. Hệ thống Farsite [1] là một hệ thống file phân tán không sử dụng bất kỳ máy chủ tập trung nào như NFS (Network File System). Farsite đạt được tính khả dụng cao và khả năng mở rộng bằng replication. Google File System (GFS) [6] là một hệ thống file phân tán khác được xây dựng để lưu trữ trạng thái các ứng dụng nội bộ của Google. GFS sử dụng thiết kế đơn giản với một server chính duy nhất để lưu trữ toàn bộ metadata và nơi dữ liệu được chia thành các chunk (phần) và được lưu trữ trong các chunkserver. Bayou là một hệ thống database quan hệ phân tán có các thao tác khi bị ngắt kết nối và cung cấp tính nhất quán đến cùng của dữ liệu [21].
Trong số các hệ thống này, Bayou, Coda và Ficus có các thao tác khi bị ngắt kết nối và có khả năng phục hồi trước các sự cố như phân vùng mạng và mất điện. Các hệ thống này khác nhau về thủ tục giải quyết xung đột. Chẳng hạn, Coda và Ficus thực hiện giải quyết xung đột ở cấp hệ thống và Bayou cho phép giải quyết ở cấp ứng dụng. Tuy nhiên, tất cả chúng đều đảm bảo eventual consistency. Tương tự như các hệ thống này, Dynamo cho phép tiếp tục đọc và ghi ngay cả khi phân vùng mạng và giải quyết các xung đột bằng các cơ chế giải quyết xung đột khác nhau. Các hệ thống lưu trữ khối phân tán như FAB [18] chia các object có kích thước lớn thành các block nhỏ hơn và lưu trữ từng block theo cách có tính khả dụng cao. So với các hệ thống này, kho lưu trữ key-value phù hợp hơn trong trường hợp này vì: (a) nó nhằm mục đích lưu trữ các object tương đối nhỏ (kích thước < 1MB) và (b) kho lưu trữ key-value dễ dàng định cấu hình hơn trên mỗi hệ thống. Antiquity là một hệ thống lưu trữ phân tán diện rộng được thiết kế để xử lý nhiều lỗi server [23]. Nó sử dụng secure log để bảo toàn tính toàn vẹn của dữ liệu, replicate từng log trên nhiều server để đảm bảo độ bền và sử dụng các giao thức chịu lỗi Byzantine để đảm bảo tính nhất quán của dữ liệu. Ngược lại với Antiquity, Dynamo không tập trung vào vấn đề toàn vẹn và bảo mật dữ liệu mà được xây dựng cho một môi trường đáng tin cậy. Bigtable là một hệ thống lưu trữ phân tán để quản lý dữ liệu có cấu trúc. Nó duy trì một map thưa, được sắp xếp, đa chiều và cho phép các ứng dụng truy cập dữ liệu của chúng bằng nhiều thuộc tính [2]. So với Bigtable, Dynamo nhắm đến các ứng dụng chỉ yêu cầu quyền truy cập key-value với trọng tâm chính là tính khả dụng cao, nơi các bản cập nhật không bị từ chối ngay cả khi có phân vùng mạng hoặc lỗi server.
Các hệ thống database quan hệ truyền thống sử dụng sao chép thì tập trung vào vấn đề đảm bảo tính nhất quán mạnh cho dữ liệu được sao chép. Mặc dù tính nhất quán mạnh cung cấp cho người viết ứng dụng một mô hình lập trình thuận tiện, nhưng các hệ thống này bị hạn chế về khả năng mở rộng và tính khả dụng [7]. Các hệ thống này không có khả năng xử lý các phân vùng mạng vì chúng thường cung cấp sự đảm bảo tính nhất quán mạnh.
3.3. Thảo luận
Dynamo khác với các hệ thống lưu trữ phi tập trung nói trên về các yêu cầu của nó. Đầu tiên, Dynamo chủ yếu nhắm mục tiêu vào các ứng dụng cần data store “luôn ghi được”, nơi không có bản cập nhật nào bị từ chối do lỗi hoặc ghi đồng thời. Đây là một yêu cầu quan trọng đối với nhiều ứng dụng của Amazon. Thứ hai, như đã nhắc trước đó, Dynamo được xây dựng cho cơ sở hạ tầng trong một domain quản trị duy nhất, nơi tất cả các node được coi là đáng tin cậy. Thứ ba, các ứng dụng sử dụng Dynamo không yêu cầu hỗ trợ namespace phân cấp (chuẩn mực trong nhiều hệ thống file) hoặc lược đồ quan hệ phức tạp (được database truyền thống hỗ trợ). Thứ tư, Dynamo được xây dựng cho các ứng dụng nhạy cảm với độ trễ, yêu cầu thực hiện ít nhất 99,9% thao tác đọc và ghi trong vòng vài trăm mili giây. Để đáp ứng các yêu cầu nghiêm ngặt về độ trễ này, chúng tôi bắt buộc phải tránh định tuyến các request qua nhiều node (đây là thiết kế điển hình được một số hệ thống hash table phân tán như Chord và Pastry áp dụng). Điều này là do định tuyến nhiều bước làm tăng sự thay đổi về thời gian response, do đó làm tăng độ trễ ở phân vị cao hơn. Dynamo có thể được mô tả như một DHT (Distributed hash table - bảng băm phân tán) zero-hop, trong đó mỗi node duy trì đủ thông tin định tuyến cục bộ để định tuyến trực tiếp request đến node thích hợp.
4. Kiến trúc hệ thống
Kiến trúc của một hệ thống lưu trữ hoạt động trong một môi trường thực tế khá phức tạp. Ngoài thành phần lưu trữ dữ liệu thực tế, hệ thống cần có các giải pháp mạnh mẽ và có thể mở rộng để cân bằng tải, phát hiện và khắc phục lỗi, xử lý quá tải, đồng bộ hoá các replica, chuyển trạng thái, lập lịch công việc, sắp xếp và định tuyến request, cảnh báo và giám sát hệ thống, quản lý cấu hình. Chúng ta sẽ không đi vào mô tả chi tiết từng giải pháp, mà chỉ tập trung vào các kỹ thuật hệ thống phân tán cốt lõi được sử dụng trong Dynamo: phân vùng (partitioning), sao chép (replication), phiên bản hóa dữ liệu (data versioning), giao thức thành viên (membership) xử lý lỗi (failure handling) và mở rộng quy mô (scaling).
| Vấn đề | Kỹ thuật | Lợi thế |
|---|---|---|
| Partitioning | Consistent hashing | Khả năng mở rộng gia tăng |
| Khả năng ghi dữ liệu có tính khả dụng cao | Vector clocks có đối chiếu trong quá trình đọc | Kích thước version độc lập với tốc độ update |
| Xử lý lỗi tạm thời | Sloppy Quorum và Hinted handoff | Bảo đảm tính khả dụng và độ bền cao khi một số replica bị chết |
| Hồi phục sau các lỗi dai dẳng | Phản entropy với cây Merkle | Đồng bộ các replica phân kỳ ở background |
| Giao thức thành viên và phát hiện lỗi | Giao thức thành viên và phát hiện lỗi dựa trên gossip | Bảo đảm tính đối xứng và tránh có node đặc biệt để lưu membership và thông tin trạng thái các node khác |
Bảng 1 trên đây giới thiệu tóm tắt danh sách các kỹ thuật mà Dynamo sử dụng cùng lợi thế tương ứng của mỗi kỹ thuật.
4.1. Giao diện hệ thống
Dynamo lưu trữ các object (đối tượng) liên kết với một key (khoá) thông qua một giao diện đơn giản; nó gồm hai thao tác: get() và put(). Thao tác get(key) định vị các replica chứa object liên kết với key trong hệ thống lưu trữ và trả về một object duy nhất hoặc mảng các object với version xung đột cùng với một context. Thao tác put(key, context, object) sẽ xác định các replica nơi mà object nên được cho vào dựa trên key liên kết, và ghi các object vào các replica đó trên đĩa. context sẽ mã hoá metadata hệ thống về object mà không tiết lộ với caller và nó chứa một số thông tin khác như version của object. Thông tin trong context được lưu cùng với object nên nó có thể được hệ thống sử dụng để kiểm tra tính đúng đắn của object trong put request.
Dynamo coi key và object trong put request là một mảng bytes thông thường. Nó sẽ dùng MD5 hash lên key để tạo ra một identifier 128 bit, identifier này sẽ được dùng để xác định node chịu trách nhiệm lưu dữ liệu dựa trên key này.
4.2. Thuật toán phân vùng
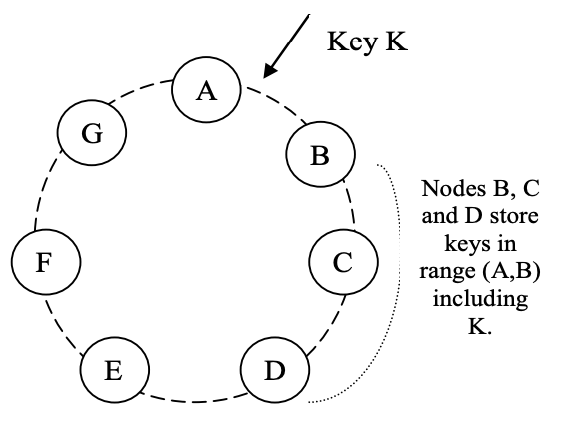
Một trong những yêu cầu chính trong thiết kế của Dynamo là nó phải có khả năng mở rộng gia tăng. Điều này yêu cầu một cơ chế phân vùng data tự động trên một tập các node (máy chủ lưu trữ) trong hệ thống. Lược đồ phân vùng của Dynamo dựa trên consistent hashing để phân phối tải trên nhiều máy chủ lưu trữ. Trong consistent hashing [10], phạm vi output của hàm hash được xem là một không gian vòng cố định hay ngắn gọn là "vòng" (nghĩa là xếp các giá trị hash trên một hình tròn, giá trị hash lớn nhất và nhỏ nhất liền kề với nhau). Mỗi node trong hệ thống được gán một giá trị ngẫu nhiên trong không gian này, được gọi là "vị trí" trên vòng. Mỗi data item (được xác định bởi một key) được gán cho một node bằng cách hash key của data item đó để cho ra vị trí trên vòng, sau đó đi theo chiều kim đồng hồ để tìm node đầu tiên với vị trí lớn hơn vị trí của item. Vì thế, mỗi node sẽ chịu trách nhiệm cho một vùng trên vòng giữa node đó và node ngay trước nó trên vòng. Lợi thế cơ bản của consistent hashing là khi thêm một node mới vào, nó chỉ ảnh hưởng đến các node liền kề với nó trên vòng, mà không ảnh hưởng đến các node còn lại.
Thuật toán consistent hashing cơ bản có một số vấn đề. Thứ nhất, việc gán ngẫu nhiên vị trí của mỗi node trên vòng sẽ dẫn đến phân bố data và tải không đồng đều. Thứ hai, thuật toán cơ bản này không tính đến tính không đồng nhất về hiệu suất của các node. Để giải quyết những vấn đề này, Dynamo sử dụng một biến thể của consistent hashing (tương tự biến thể trong [10, 20]): thay vì map một node đến một điểm trên hình tròn, mỗi node sẽ được gán vào nhiều điểm. Để làm được điều này, Dynamo sử dụng khái niệm "node ảo" (virtual node). Node ảo sẽ giống như node duy nhất trong hệ thống, nhưng mỗi node sẽ chịu trách nhiệm cho nhiều node ảo. Thực tế, khi một node mới được thêm vào hệ thống, nó được gán nhiều vị trí (sau này được gọi là các "token") trên vòng. Quá trình tinh chỉnh lược đồ phân vùng của Dynamo sẽ được nói đến trong phần 6.
Dùng các node ảo sẽ có những ích lợi như sau:
- Nếu một node bị chết (do lỗi hoặc bảo trì), tải của node này sẽ được chia đều cho các node còn lại.
- Khi một node sống lại, hoặc node mới được thêm vào, node này sẽ được chia một phần tương đương tải từ các node khác.
- Số node ảo mà một node thật chịu trách nhiệm có thể được xác định dựa trên hiệu suất của nó, dựa vào tính không đồng nhất trong cơ sở hạ tầng vật lý.
4.3. Sao chép (Replication)
Để có tính khả dụng và độ bền cao, Dynamo replicate data trên nhiều máy chủ khác nhau. Mỗi data item sẽ được replicate lên N máy chủ khác, trong đó N là tham số được cấu hình trên mỗi instance của Dynamo. Mỗi khoá k được gán vào mỗi coordinator node (đã nói ở phần trước). Coordinator này sẽ chịu trách nhiệm replicate các data item trong đoạn mà nó quản lý. Ngoài việc lưu trữ các key trong đoạn mà nó kiểm soát, coordinator sẽ replicate các key này lên N-1 node tiếp theo (theo chiều kim đồng hồ) trên vòng. Điều này sẽ khiến hệ thống trở thành nơi mỗi node sẽ chịu trách nhiệm cho phần trên vòng giữa nó và node thứ N trước nó (kể cả đoạn mà node thứ N trước nó quản lý). Trong hình 2, node B replicate khoá k đến node C và D cùng với việc lưu trữ khoá k trên chính node B. Node D sẽ lưu các khoá trong các đoạn (A, B], (B, C], (C, D].
Danh sách các node chịu trách nhiệm lưu một khoá nào đó được gọi là danh sách ưu tiên (preference list). Hệ thống được thiết kế (như được giải thích trong phần 4.8) sao cho mọi node trong hệ thống có thể xác định node nào sẽ nào trong danh sách này cho bất kỳ khoá nào. Để giải quyết lỗi node, danh sách ưu tiên sẽ chứa nhiều hơn N node. Lưu ý rằng với việc sử dụng các node ảo, có thể N node tiếp theo cho một khoá có thể là của ít hơn N node thật (ví dụ như một node thật có nhiều hơn một node ảo trong N node tiếp theo). Để giải quyết vấn đề này, danh sách ưu tiên của một khoá sẽ được xây dựng bằng cách bỏ qua một số vị trí trong vòng để đảm bảo rằng danh sách chỉ chứa các node thật riêng biệt nhau.
4.4. Phiên bản hóa dữ liệu (Data Versioning)
Dynamo cung cấp tính nhất quán đến cùng, nghĩa là cho phép các cập nhật đến cuối cùng sẽ được phân bố đến tất cả các replica. Một lời gọi hàm put() sẽ trả về cho người gọi trước khi các cập nhật đến được các replica. Điều này có thể dẫn đến trường hợp gọi hàm get() ngay sau đó sẽ trả về một object không chứa cập nhật mới nhất. Nếu không có lỗi xảy ra thì thời gian phân bố sẽ nằm trong một khoảng nào đó. Tuy nhiên, trong trường hợp lỗi (ví dụ như server sập hoặc phân vùng mạng), các cập nhật có thể sẽ không đến tất cả các replica trong một khoảng thời gian khá lớn.
Có một lớp các ứng dụng trong nền tảng Amazon có thể chịu được những sự thiếu nhất quán như vậy và có thể được xây dựng để hoạt động trong các điều kiện như thế. Ví dụ, ứng dụng giỏ hàng yêu cầu rằng thao tác "Thêm hàng vào giỏ hàng" không bao giờ được bỏ qua hoặc từ chối. Nếu trạng thái mới nhất của giỏ hàng không khả dụng, và người dùng thực hiện thay đổi cho một version cũ hơn của giỏ hàng thì thay đổi đó vẫn có thể được giữ lại. Nhưng đồng thời, nó không được thay thế trạng hái hiện tại của giỏ hàng, trạng thái này có thể chứa những thay đổi quan trọng. Lưu ý rằng cả hai thao tác "thêm vào giỏ hàng" và "bỏ khỏi giỏ hàng" đều được chuyển thành các put() request đến Dynamo. Khi khách muốn thêm một mặt hàng vào (hoặc xoá khỏi) giỏ hàng, và version mới nhất của giỏ hàng không khả dụng, mặt hàng đó sẽ được thêm vào (hoặc xoá khỏi) version cũ hơn và các version khác nhau sẽ được đối chiếu sau.
Để đảm bảo được điều này, Dynamo coi kết quả của mỗi thay đổi là một version mới và không chỉnh sửa được của dữ liệu. Nó cho phép nhiều version của một object xuất hiện trong hệ thống ở cùng một thời điểm. Trong hầu hết các trường hợp, version mới sẽ bao gồm (các) version trước đó, và bản thân hệ thống có thể xác định version chính thức (đối chiếu cú pháp). Tuy nhiên, việc phân nhánh version có thể xảy ra khi có lỗi, cùng với các cập nhật cùng thời điểm, dẫn tới các version xung đột của cùng một object. Trong những trường hợp này, hệ thống không thể đối chiếu nhiều version của cùng object và khách hàng phải thực hiện đối chiếu để thu gọn nhiều nhánh của dữ liệu thành một (đối chiếu ngữ nghĩa). Một ví dụ của thao tác thu gọn là "hợp nhất" các version khác nhau của giỏ hàng. Với cơ chế đối chiếu này, thao tác "thêm vào giỏ hàng" sẽ không bao giờ mất. Tuy nhiên, những mặt hàng đã xoá có thể xuất hiện lại.
Điều quan trọng là phải hiểu rằng một số loại lỗi nhất định có thể dẫn đến việc hệ thống không chỉ có hai mà có nhiều version của cùng một dữ liệu. Các bản cập nhật khi có phân vùng mạng và lỗi node có thể dẫn đến một object có lịch sử version khác nhau mà hệ thống sẽ cần phải điều chỉnh trong tương lai. Điều này đòi hỏi chúng tôi phải thiết kế ứng dụng xác nhận rõ ràng khả năng có nhiều version của cùng một dữ liệu (để không mất bất kỳ cập nhật nào).
Dynamo sử dụng vector clock [12] để nắm bắt quan hệ nhân quả giữa các version khác nhau của cùng một object. Một vector clock là một danh sách các cặp (node, bộ đếm). Một vector clock được liên kết với một version của mọi object. Ta có thể xác định hai version của một object nằm trên các nhánh song song hay có thứ tự nhân quả bằng cách kiểm tra các vector clock của chúng. Nếu bộ đếm trên clock của object đầu tiên nhỏ hơn hoặc bằng tất cả các node trong clock thứ hai thì cái đầu tiên sẽ xảy ra trước cái thứ hai và có thể bỏ đi. Ngược lại, hai thay đổi này được coi là có xung đột và cần phải điều chỉnh.
Trong Dynamo, khi một khách hàng muốn cập nhật một object, cần phải xác định version nào sẽ được cập nhật. Điều này được thực hiện bằng việc nhận context truyền bởi khách hàng từ thao tác đọc trước đó, trong đó sẽ bao gồm thông tin vector clock. Khi xử lý request đọc, nếu Dynamo có quyền truy cập vào nhiều nhánh không thể đối chiếu về mặt cú pháp, nó sẽ trả về tất cả các object ở các node lá, với thông tin version tương ứng trong context. Một cập nhật dùng context này được coi là đã đối chiếu các version khác nhau và các nhánh sẽ thu gọn lại thành một version mới duy nhất.
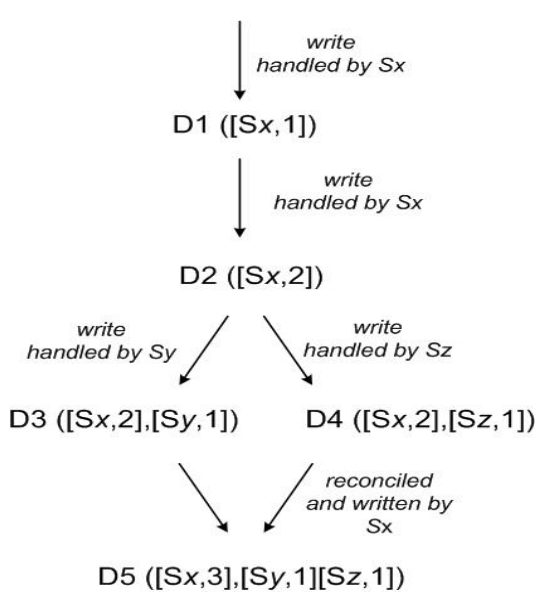
Để minh hoạ việc sử dụng vector clock, ta hãy cùng xem xét ví dụ trong hình 3. Một client ghi một object mới. Node (gọi là Sx đi) xử lý việc ghi key này sẽ tăng số thứ tự của nó lên và dùng số này để tạo vector clock của dữ liệu. Hệ thống bây giờ sẽ có object D1 và clock của nó là [(Sx, 1)]. Client sau đó cập nhật object này. Giả sử cùng node đó xử lý request này. Hệ thống giờ sẽ có object D2 và clock là [(Sx, 2)]. D2 theo sau D1 và do đó ghi đè lên D1, tuy nhiên có thể có các replica của D1 tồn tại ở các node mạng khác chưa nhìn thấy D2. Giả sử rằng cùng một client cập nhật object lần nữa và một server khác (gọi là Sy đi) xử lý request. Hệ thống giờ sẽ có data D3 và clock là [(Sx, 2), (Sy, 1)].
Tiếp theo, giả sử một client khác đọc D2 và cập nhật nó, và một node khác (gọi là Sz đi) thực hiện việc ghi. Hệ thống giờ sẽ có D4 (con của D2) với vector clock là [(Sx, 2), (Sz, 1)]. Một node nhận biết D1 hoặc D2 có thể xác định, khi nhận D4 và clock của nó, rằng D1 và D2 bị ghi đè bởi dữ liệu mới và có thể được dọn đi. Node nhận biết D3 và nhận D4 sẽ thấy rằng không có quan hệ nhân quả giữa chúng. Nói cách khác, có các thay đổi trong D3 và D4 không phản ánh lẫn nhau. Cả hai version này phải được lưu lại và trình bày cho client (khi đọc) để đối chiếu ngữ nghĩa.
Giờ giả sử client nào đó đọc cả D3 và D4 (context sẽ phản ánh rằng cả hai giá trị được trả về khi đọc). Context của thao tác đọc là một bản tóm tắt của các clock D3 và D4, cụ thể là [(Sx, 2), (Sy, 1), (Sz, 1)]. Nếu client thực hiện đối chiếu và node Sx điều phối việc ghi, Sx sẽ cập nhật số thứ tự của nó trong clock. Dữ liệu mới D5 sẽ có clock như sau: [(Sx, 3), (Sy, 1), (Sz, 1)].
Một vấn đề có thể xảy ra với vector clock là kích thước của nó có thể tăng lên nhiều nếu nhiều server phối hợp ghi vào một object. Trong thực tế, điều này khó xảy ra vì việc ghi thường xuyên được xử lý bởi một trong N node trong danh sách ưu tiên. Trong trường hợp phân vùng mạng hoặc server chết, request ghi có thể được xử lý bởi các node không nằm trong top N node được ưu tiên, khiến kích thước vector clock tăng lên. Trong các trường hợp như vậy, ta nên giới hạng kích thước của vector clock. Dynamo sử dụng lược đồ cắt ngắn clock như sau: Cùng với mỗi cặp (node, bộ đếm), Dynamo lưu timestamp cho biết lần cuối cùng cập nhật data item. Khi số cặp (node, bộ đếm) trong vector clock đạt ngưỡng (ví dụ như 10 chẳng hạn), cặp cũ nhất sẽ bị xoá khỏi clock. Rõ ràng là việc cắt ngắn này có thể dẫn đến sự thiếu hiệu quả trong việc điều chỉnh vì các mối quan hệ nhân quả không thể được suy ra một cách chính xác. Tuy nhiên, vấn đề này chưa xuất hiện trong thực tế nên nó chưa được điều tra kỹ lưỡng.
4.5. Thực thi các thao tác get() và put()
Bất kỳ node nào trong Dynamo cũng có thể nhận các thao tác get() và put() từ client cho bất cứ key nào. Trong phần này, để cho đơn giản, ta sẽ đi vào mô tả cách thức thực thi các thao tác này trong một môi trường không có lỗi và trong phần tiếp theo ta sẽ mô tả cách thức thực thi chúng trong một môi trường có lỗi.
Cả hai thao tác get() và put() đều được thực thi bằng cách sử dụng framework xử lý request dành riêng cho cơ sở hạ tầng Amazon thông qua HTTP. Có hai cách client có thể dùng để chọn node: (1) định tuyến request thông qua một load balancer thông thường sẽ chọn node dựa trên thông tin tải, hoặc (2) sử dụng một thư viện client có khả năng phân vùng để định tuyến request trực tiếp đến các node điều phối thích hợp. Ưu điểm của cách thứ nhất là client không cần phải liên kết bất kỳ code nào đặc biệt cho Dynamo trong ứng dụng của nó, trong khi cách thứ hai có thể đạt được độ trễ thấp hơn vì nó bỏ qua bước chuyển tiếp.
Node xử lý thao tác đọc ghi được gọi là node điều phối. Thông thường, nó nằm trong top N node trong danh sách ưu tiên. Nếu request được nhận thông qua load balancer, các request để truy cập một key có thể được định tuyến đến bất kỳ node ngẫu nhiên nào trên vòng. Trong trường hợp này, node nhận request sẽ không điều phối request nếu nó không nằm trong top N của danh sách ưu tiên của key được request. Thay vào đó, node này sẽ chuyển tiếp request đến node đầu tiên trong số top N node trong danh sách ưu tiên.
Các thao tác đọc và ghi sẽ liên quan đến N node còn sống đầu tiên trong danh sách ưu tiên, bỏ qua các node bị chết hoặc không truy cập được. Khi tất cả các node còn sống, top N node trong danh sách ưu tiên của một key sẽ được truy cập. Khi có node chết hoặc phân vùng mạng, các node được xếp hạng thấp hơn trong danh sách ưu tiên sẽ được truy cập.
Để duy trì tính nhất quán giữa các replica, Dynamo sử dụng một giao thức nhất quán tương tự thứ được sử dụng trong các hệ thống quorum. Giao thức này có hai giá trị cấu hình chính: R và W. R là số lượng node tối thiểu phải tham gia vào một thao tác đọc thành công. W là số lượng node tối thiểu phải tham gia vào một thao tác ghi thành công. Đặt R và W sao cho R + W > N sẽ tạo ra một hệ thống như quorum. Trong mô hình này, độ trễ của một thao tác get (hoặc put) sẽ phụ thuộc vào node chậm nhất trong R (hoặc W) node. Vì lý do này, R và W thường được cấu hình để nhỏ hơn N, để cải thiện độ trễ.
Khi nhận được request put() cho môt key, node điều phối sẽ sinh ra vector clock cho version mới và viết version mới này vào chính nó. Node điều phối sẽ gửi phiên bản mới này (cùng với vector clock mới) đến N node cao nhất trong danh sách ưu tiên. Nếu ít nhất W-1 node phản hồi thành công thì việc ghi được coi là thành công (vì node điều phối đã ghi thành công rồi).
Tương tự, với request get(), node điều phối sẽ request tất cả các version hiện có cho key đó từ N node cao nhất trong danh sách ưu tiên của key, sau đó đợi R phản hồi thành công trước khi trả kết quả cho client. Nếu node điều phối nhận được nhiều hơn một versuon của dữ liệu, nó sẽ trả về tất cả các version không có quan hệ nhân quả này về cho client. Các version này sẽ được đối chiếu và version được đối chiếu sẽ được ghi trở lại.
4.6. Xử lý lỗi: Hinted Handoff
Nếu Dynamo sử dụng cách tiếp cận quorum truyền thống, nó sẽ không khả dụng khi server có lỗi và phân vùng mạng, và sẽ làm giảm độ bền hệ thống, ngay cả trong điều kiện lỗi đơn giản nhất. Để giải quyết điều này, nó sẽ không áp dụng các quy tắc quorum nghiêm ngặt mà sẽ sử dụng "sloppy quorum"; tất cả các thao tác đọc và ghi sẽ được thực hiện trên N node đầu tiên trong danh sách ưu tiên, mà không nhất thiết phải là N node đầu tiên mà nó gặp khi đi theo vòng consistent hashing.
Xét ví dụ về cấu hình Dynamo trong hình 2 với N = 3. Trong ví dụ này, nếu node A chết hoặc không truy cập được trong khi thực hiện thao tác ghi, bản sao mà thường sẽ được lưu trên A sẽ được gửi đến node D. Việc này được thực hiện để đảm bảo tính khả dụng và độ bền như mong muốn. Bản sao được gửi đến D sẽ có một hint trong metadata của nó cho biết node nào là node đích (trong trường hợp này là A). Các node nhận được bản sao sẽ giữ chúng trong một database cục bộ riêng biệt được quét định kỳ. Khi phát hiện ra rằng A sống lại, D sẽ cố gắng gửi bản sao đến A. Khi việc chuyển thành công, D có thể xoá object khỏi database cục bộ mà không làm giảm số lượng bản sao trong hệ thống.
Với hinted handoff, Dynamo đảm bảo rằng các thao tác đọc và ghi không bị lỗi do node hoặc mạng tạm thời. Các ứng dụng cần tính khả dụng cao nhất có thể đặt W = 1, đảm bảo rằng một thao tác ghi được chấp nhận nếu ít nhất một node trong hệ thống đã ghi key đó vào bộ nhớ cục bộ. Do đó, thao tác ghi chỉ bị từ chối khi tất cả các node trong hệ thống đều không khả dụng. Tuy nhiên, trong thực tế, hầu hết các dịch vụ Amazon đang hoạt động đều đặt W cao hơn để đạt được mức độ bền mong muốn. Phần 6 sẽ trình bày chi tiết hơn về cách cấu hình N, R và W.
Một hệ thống lưu trữ có tính khả dụng cao bắt buộc phải có khả năng phản ứng trước sự cố của toàn bộ (các) data center. Sự cố data center xảy ra do mất điện, lỗi hệ thống làm mát, mất mạng, thiên tai. Dynamo được cấu hình sao cho mỗi object được replicate trên nhiều data center. Cụ thể, danh sách ưu tiên của một key được xây dựng sao cho các node lưu trữ được phân bố trên nhiều data center. Các data center này được kết nối với nhau bằng các liên kết mạng tốc độ cao. Cách thức sao chép trên nhiều data center cho phép hệ thống xử lý sự cố toàn bộ data center mà không làm gián đoạn dữ liệu.
4.7. Xử lý lỗi dai dẳng: Đồng bộ replica
Hinted handoff hoạt động ngon nhất nếu tỉ lệ thay đổi thành viên (node) thấp và sự cố node chỉ là nhất thời. Có những trường hợp mà các bản sao hinted không khả dụng trước khi chúng có thể được trả về node ban đầu. Để giải quyết vấn đề này và các vấn đề khác về độ bền, Dynamo triển khai giao thức phản entropy (đồng bộ replica) để giữ các bản sao được đồng bộ.
Để phát hiện những sự bất nhất giữa các replica nhanh hơn và giảm thiểu lượng dữ liệu được truyền, Dynamo dùng cây Merkle [13]. Cây Merkle là một cây hash trong đó các node lá là các giá trị hash của từng key riêng lẻ. Các node cha cao hơn trong cây là các giá trị hash của các node con tương ứng. Ưu điểm chính của cây Merkle là mỗi nhánh của cây có thể được kiểm tra một cách độc lập mà không cần các node phải tải toàn bộ cây hoặc toàn bộ tập dữ liệu. Hơn nữa, cây Merkle giúp giảm thiểu lượng dữ liệu cần được truyền trong quá trình đồng bộ. Ví dụ, nếu giá trị hash của hai cây giống nhau, thì các giá trị của các node lá trong cây cũng giống nhau và các node không cần đồng bộ. Nếu không, nó có nghĩa là các giá trị của một số bản sao khác nhau. Trong trường hợp này, các node có thể trao đổi các giá trị hash của các node con và quá trình tiếp tục cho đến khi nó đạt đến các node lá của cây, tại đó các host có thể xác định các key không đồng bộ. Cây Merkle giảm thiểu lượng dữ liệu cần được truyền trong quá trình đồng bộ và giảm số lần đọc đĩa trong quá trình phản entropy.
Dynamo sử dụng cây Merkle cho phản entropy như sau: Mỗi node duy trì một cây Merkle riêng biệt cho mỗi khoảng key (tập hợp các key được bao phủ bởi một node ảo). Điều này cho phép các node so sánh xem các key trong một khoảng key có được cập nhật hay không. Trong kế hoạch này, hai node trao đổi các node gốc của cây Merkle tương ứng với các khoảng key mà chúng chia sẻ. Sau đó, sử dụng cách duyệt cây đã được mô tả ở trên, các node xác định xem chúng có bất kỳ sự khác biệt nào không và thực hiện hành động phản entropy thích hợp. Nhược điểm là nhiều khoảng key thay đổi khi một node tham gia hoặc rời khỏi hệ thống, do đó yêu cầu tính toán lại (các) cây. Tuy nhiên, vấn đề này được giải quyết bằng cách phân chia một cách tinh vi hơn, sẽ được mô tả trong phần 6.2.
4.8. Giao thức thành viên và phát hiện sự cố
4.8.1. Vòng thành viên
Trong môi trường của Amazon, node bị chết (do sự cố hoặc bảo trì) thường ngắn nhưng đôi khi có thể dài hơn dự kiến. Sự cố node hiếm khi dẫn đến việc loại bỏ hoàn toán node đó và vì thế sẽ không dẫn đến việc tái cân bằng phân vùng hoặc sửa chữa các bản sao không thê truy cập được. Tương tự, lỗi người dùng có thể dẫn đến việc khởi động lại các node Dynamo. Vì những lý do này, ta nên sử dụng một cơ chế rõ ràng để khởi động và loại bỏ các node khỏi vòng. Một admin sẽ sử dụng một command-line tool hoặc browser để kết nối đến một node Dynamo và thực hiện một thay đổi thành viên để thêm một node vào vòng hoặc loại bỏ một node khỏi vòng. Node nhận yêu cầu sẽ ghi lại thay đổi thành viên và thời gian thực hiện vào bộ nhớ lưu trữ. Các thay đổi thành viên tạo thành một lịch sử vì các node có thể bị loại bỏ và thêm lại nhiều lần. Một giao thức gossip sẽ phân bố các thay đổi thành viên và duy trì một giao diện thành viên nhất quán đến cùng. Mỗi node sẽ liên hệ với một node ngẫu nhiên mỗi giây và hai node sẽ cập nhật lịch sử thay đổi thành viên của mình một cách hiệu quả.
Khi một node được khởi động lần đầu, nó chọn một tập các token (node ảo trong không gian consistent hash) và ánh xạ các node vào các tập token tương ứng của chúng. Ánh xạ được lưu trữ trên đĩa và ban đầu chỉ chứa node cục bộ và tập token. Các ánh xạ được lưu trữ trên các node Dynamo khác nhau được điều phối trong cùng một giao tiếp để điều phối lịch sử thay đổi thành viên. Do đó, phân vùng và thông tin vị trí cũng được phân phối thông qua giao thức gossip và mỗi node lưu trữ biết được các khoảng token được xử lý bởi các node khác. Điều này cho phép mỗi node chuyển tiếp các thao tác đọc / ghi của một key trực tiếp đến tập hợp các node thích hợp.
4.8.2. External Discovery
Cơ chế ở trên có thể tạm thời tạo ra được một vòng Dynamo được phân vùng hợp lý. Ví dụ, admin có thể liên hệ với node A để thêm A vào vòng, sau đó liên hệ với node B để thêm B vào vòng. Trong kịch bản này, node A và B sẽ xem chúng là thành viên của vòng, nhưng chưa nhận ra nhau trong vòng. Để ngăn chặn các phân vùng logic, một số node Dynamo sẽ đóng vai trò seed. Seed là các node được phát hiện thông qua một cơ chế bên ngoài và được biết đến bởi tất cả các node. Vì tất cả các node cuối cùng sẽ đồng bộ thành viên của mình với seed, do vậy việc phân vùng logic rất khó xảy ra. Seed có thể được lấy từ static configuration hoặc từ configuration service. Thông thường, seed là các node có đầy đủ chức năng trong vòng Dynamo.
4.8.3. Phát hiện sự cố
Tính năng phát hiện sự cố trong Dynamo được dùng để tránh việc giao tiếp với các node bị chết trong khi đang thực hiện các thao tác get() và put() cũng như khi chuyển phân vùng và các bản sao hinted. Để tránh việc cố gắng giao tiếp với các node chết, chỉ cần một định nghĩa đơn giản về phát hiện sự cố là đủ: node A sẽ xem node B chết khi node B không trả lời node A (ngay cả khi B trả lời node C). Khi có tốc độ ổn định các client request tạo ra liên lạc nội bộ trong vòng Dynamo, node A nhanh chóng nhận ra rằng node B không trả lời khi B thất bại trong việc trả lời tin nhắn của A; Node A sau đó sử dụng các node thay thế để phục vụ các request tương ứng với các phân vùng của B; A định kỳ thử lại B để kiểm tra việc phục hồi của B. Trong trường hợp không có request client nào để tạo ra liên lạc giữa hai node, ta không cần phải biết rằng node kia có thể truy cập được hay không.
Các giao thức phát hiện sự cố phi tập trung sử dụng một giao thức kiểu gossip đơn giản, trong đó cho phép mỗi node trong hệ thống tìm hiểu việc thêm vào (hoặc bớt đi) các node khác. Để biết thêm thông tin về các bộ phát hiện sự cố phi tập trung và các tham số ảnh hưởng đến sự chính xác của chúng, mời bạn tham khảo [8]. Các thiết kế ban đầu của Dynamo dùng một bộ phát hiện lỗi phi tập trung để duy trì một view nhất quán về trạng thái sự cố. Sau đó, người ta xác định rằng các phương thức thêm hay bớt node rõ ràng loại bỏ nhu cầu về một view toàn cầu về trạng thái sự cố. Điều này là vì các node được thông báo về việc thêm vào và loại bỏ các node vĩnh viễn bằng các phương thức thêm và bớt node rõ ràng và các sự cố tạm thời được phát hiện bởi các node riêng lẻ khi chúng không thể giao tiếp với các node khác (trong khi chuyển tiếp các request).
4.9. Thêm / bớt node lưu trữ
Khi một node mới (gọi là X) được thêm vào hệ thống, nó được gán một số token được phân tán ngẫu nhiên trên vòng. Đối với mỗi khoảng key được giao cho node X, có thể có một số node (ít hơn hoặc bằng N) đang chịu trách nhiệm xử lý các key nằm trong khoảng token của nó. Do phân bổ khoảng key cho X, một số node hiện có không còn phải giữ một số key và các node này chuyển các key này cho X. Xét một ví dụ khi node X được thêm vào vòng như trong hình 2 giữa A và B. Khi X được thêm vào hệ thống, nó chịu trách nhiệm lưu trữ các key trong các khoảng (F, G], (G, A] và (A, X]. Do đó, các node B, C và D không còn phải lưu trữ các key trong các khoảng tương ứng này. Do đó, các node B, C và D sẽ chuyển các key thích hợp cho X sau khi X xác nhận. Khi một node bị xóa khỏi hệ thống, việc phân bổ lại các key xảy ra theo một quá trình ngược lại.
Kinh nghiệm vận hành đã cho thấy cách tiếp cận này phân phối key đồng đều trên các node lưu trữ, điều này quan trọng để đáp ứng các yêu cầu về độ trễ và đảm bảo việc khởi động nhanh chóng. Cuối cùng, việc thêm một bước xác nhận giữa node cho và node nhận đảm bảo rằng node nhận không nhận bất kỳ chuyển tiếp trùng lặp nào trong một khoảng key cho trước.
5. Cài đặt
Trong Dynamo, mỗi node lưu trữ có 3 thành phần chính: điều phối request, giao thức thành viên và phát hiện sự cố, và một engine lưu trữ cục bộ. Tất cả các thành phần này được cài đặt bằng Java.
Thành phần lưu trữ cục bộ của Dynamo cho phép các engine lưu trữ khác nhau được cài vào. Các engine lưu trữ được sử dụng là Berkeley Database (BDB) Transactional Data Store, BDB Java Edition, MySQL, và một in-memory buffer với persistent backing store. Lý do chính để chọn thiết kế linh hoạt như vậy là để chọn engine lưu trữ phù hợp nhất cho các ứng dụng. Ví dụ, BDB có thể xử lý các object có kích thước thường là hàng chục kilobyte trong khi MySQL có thể xử lý các object có kích thước lớn hơn. Các ứng dụng chọn engine lưu trữ cục bộ của Dynamo dựa trên phân phối kích thước object của chúng. Đa số các phiên bản thực tế của Dynamo sử dụng BDB Transactional Data Store.
Thành phần điều phối request được xây dựng dựa trên nền tảng tin nhắn hướng sự kiện trong đó quy trình xử lý tin nhắn được chia thành nhiều giai đoạn tương tự như kiến trúc SEDA [24]. Tất cả các thông tin liên lạc được cài đặt bằng Java NIO channel. Điều phối viên sẽ thực hiện các request đọc / ghi thay cho client bằng cách thu thập dữ liệu từ một hay nhiều node (khi đọc) hoặc lưu dữ liệu vào một hay nhiều node (khi ghi). Mỗi request từ client sẽ tạo ra một máy trạng thái trên node nhận được request. Trạng thái máy này chứa tất cả các logic để xác định các node chịu trách nhiệm cho một key, gửi các request, đợi phản hồi, thực hiện các bước thử lại, xử lý các phản hồi và đóng gói kết quả trả về cho client. Mỗi máy trạng thái thực hiện đúng một request từ client. Ví dụ, một thao tác đọc thực hiện các giai đoạn sau: (1) gửi các request đọc đến các node, (2) đợi phản hồi thành công từ một số tối thiểu các node, (3) nếu số lượng phản hồi nhỏ hơn số lượng yêu cầu, request thất bại, (4) ngược lại, thu thập tất cả các version dữ liệu và xác định version nào sẽ được trả về và (5) nếu việc versioning được bật, thực hiện phân giải cú pháp và tạo ra một context ghi tùy ý chứa vector clock bao gồm tất cả các version còn lại. Để ngắn gọn, các giai đoạn xử lý lỗi và thử lại được bỏ qua.
Sau khi response của thao tác đọc được trả về cho caller, máy trạng thái sẽ đợi một khoảng thời gian nhỏ để nhận các response chưa được xử lý. Nếu các version cũ được trả về trong bất kỳ response nào, máy trạng thái sẽ cập nhật các node đó với version mới nhất. Quá trình này được gọi là phục hồi đọc vì nó phục hồi các bản sao đã bỏ lỡ một cập nhật gần đây vào một thời điểm thuận tiện và giảm thiểu việc phải thực hiện các bước phục hồi trong quá trình phản entropy.
Như đã nói ở trên, các request ghi được điều phối bởi một trong top N node trong danh sách ưu tiên. Dù sẽ là lý tưởng nhất nếu chọn node đầu tiên trong top N node để điều phối các request ghi vào chung một chỗ, nó sẽ tạo ra việc phân bố không đều tải và dẫn đến việc vi phạm SLA. Điều này là vì lượng request không được phân bố đều trên các object. Để giải quyết vấn đề này, bất kỳ node nào trong top N node trong danh sách ưu tiên cũng có thể điều phối các request ghi. Cụ thể, vì mỗi request ghi thường được thực hiện ngay sau một thao tác đọc, node điều phối cho một request ghi thường là node trả lời nhanh nhất cho thao tác đọc trước đó được lưu trữ trong thông tin context của request. Tối ưu này cho phép chọn node có dữ liệu đã được đọc bởi thao tác đọc trước đó, tăng khả năng đạt được tính nhất quán "read-your-writes" và giảm độ biến động của hiệu suất xử lý request, cải thiện hiệu suất ở phân vị 99.9.
6. Kinh nghiệm và bài học
Dynamo được sử dụng bởi nhiều service với cấu hình khác nhau. Các instance này khác nhau bởi logic đối chiếu version và các đặc tính đọc / ghi quorum. Các pattern chính mà Dynamo được sử dụng là:
- Đối chiếu cụ thể về business logic: Đây là use case phổ biến nhất của Dynamo. Mỗi data object được sao chép qua nhiều node. Trong trường hợp có các version khác nhau, ứng dụng client sẽ dùng logic đối chiếu của riêng nó. Ví dụ giỏ hàng mua sắm đã được đề cập ở trên là một ví dụ điển hình cho loại này. Logic đối chiếu của nó sẽ đối chiếu các object bằng cách hợp nhất các version khác nhau của giỏ hàng mua sắm.
- Đối chiếu dựa trên timestamp: Trường hợp này khác với trường hợp trên chỉ ở chỗ cách đối chiếu. Khi có các version khác nhau, Dynamo sẽ thực hiện đối chiếu dựa trên timestamp theo kiểu "last write wins", nghĩa là object có timestamp lớn nhất sẽ được chọn là version đúng. Service duy trì thông tin phiên của khách hàng là một ví dụ điển hình cho loại này.
- Engine đọc hiệu suất cao: Trong khi Dynamo được xây dựng để là một data store "luôn có thể ghi", một số service đang tinh chỉnh các đặc tính quorum của nó và sử dụng nó như một engine đọc hiệu suất cao. Thông thường, các service này có tỷ lệ request đọc cao và chỉ có một số lượng nhỏ các update. Trong cấu hình này, thông thường R được đặt là 1 và W được đặt là N. Với các service này, Dynamo cung cấp khả năng phân vùng và sao chép dữ liệu của chúng qua nhiều node, do đó cung cấp khả năng mở rộng tăng dần. Một số service duy trì danh mục sản phẩm và các mặt hàng khuyến mãi nằm trong loại này.
Lợi thế chính của Dynamo là các ứng dụng client có thể điều chỉnh các giá trị N, R và W để đạt được mức độ hiệu suất, khả dụng và bền vững mong muốn. Ví dụ, giá trị N quyết định độ bền của mỗi object. Giá trị N thường được sử dụng là 3.
Giá trị W và R ảnh hưởng đến tính khả dụng, độ bền và tính nhất quán của object. Ví dụ, nếu W = 1, hệ thống sẽ không bao giờ từ chối một request ghi nào miễn là có ít nhất một node trong hệ thống có thể xử lý request ghi. Tuy nhiên, giá trị W và R thấp có thể làm tăng nguy cơ không nhất quán vì các request ghi được coi là thành công và trả về cho client ngay cả khi chúng không được xử lý bởi đa số các replica. Điều này cũng tạo ra một điểm yếu về độ bền khi một request ghi được trả về cho client ngay cả khi nó chỉ được lưu trữ trên một số node nhỏ trong hệ thống.
Người ta cho rằng độ bền và tính khả dụng luôn đi đôi với nhau. Tuy nhiên, điều đó không hẳn đúng ở đây. Ví dụ, điểm yếu độ bền có thể giảm đi khi tăng W. Điều này có thể làm tăng xác suất từ chối các request (do đó giảm khả dụng) vì nhiều node lưu trữ cần phải hoạt động để xử lý một request ghi.
Cấu hình (N, R, W) phổ biến được sử dụng bởi nhiều phiên bản của Dynamo là (3, 2, 2). Các giá trị này được chọn để đáp ứng các mức độ hiệu suất, độ bền, tính nhất quán và khả dụng mong muốn.
Tất cả các đo lường được trình bày trong phần này được thực hiện trên một hệ thống thực tế đang hoạt động với cấu hình (3, 2, 2) và chạy một vài trăm node với cấu hình phần cứng đồng nhất. Như đã đề cập ở trên, mỗi phiên bản của Dynamo chứa các node được đặt trong nhiều data center. Các data center này thường được kết nối thông qua các liên kết mạng tốc độ cao. Như đã đề cập ở trên, để tạo ra một response đọc (hoặc ghi) thành công, R (hoặc W) node cần phải phản hồi cho node điều phối. Rõ ràng, độ trễ mạng giữa các data center ảnh hưởng đến thời gian phản hồi và các node (và vị trí data cebter của chúng) được chọn sao cho các SLA của ứng dụng được đáp ứng.
6.1. Cân bằng hiệu suất và độ bền
Trong khi mục tiêu của Dynamo là xây dựng một data store có khả năng khả dụng cao, hiệu suất cũng là một tiêu chí quan trọng trong nền tảng của Amazon. Như đã đề cập ở trên, để cung cấp một trải nghiệm khách hàng nhất quán, các dịch vụ của Amazon đặt các mục tiêu hiệu suất ở phân vị cao (như phân vị 99.9 hoặc 99.99). Một SLA điển hình được yêu cầu của các dịch vụ sử dụng Dynamo là 99.9% các request đọc và ghi được thực hiện trong vòng 300ms.
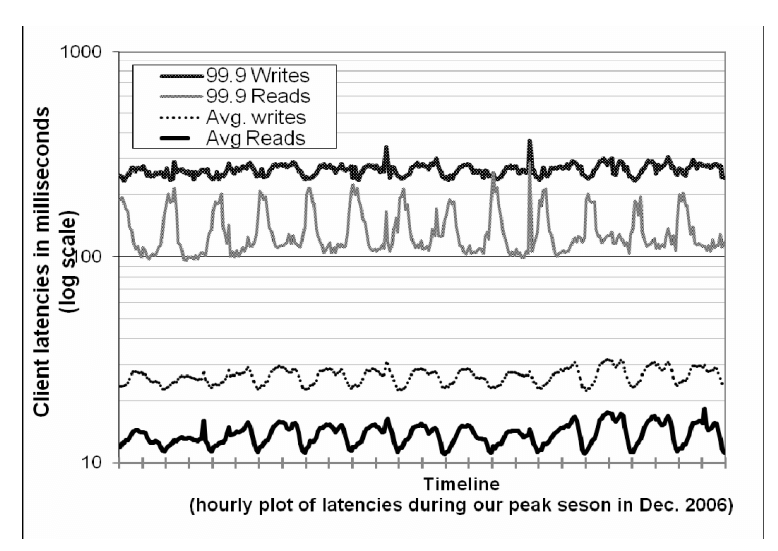
Vì Dynamo được chạy trên các thành phần phần cứng thông thường tiêu chuẩn có thông lượng I/O ít hơn nhiều so với các server doanh nghiệp cao cấp, nên việc cung cấp hiệu suất cao ổn định cho việc đọc và ghi là một nhiệm vụ không hề đơn giản. Sự tham gia của nhiều node lưu trữ trong thao tác đọc và ghi khiến việc này càng trở nên khó khăn hơn, vì hiệu suất của các thao tác này bị hạn chế bởi R và W của các replica. Hình 4 cho thấy độ trễ trung bình và phân vị 99.9 của thao tác độc và ghi trong thời gian 30 ngày. Như ta thấy, độ trễ thể hiện một mô hình ngày đêm rõ ràng, đó là kết quả của mô hình ngày đêm của tốc độ request đến. Ngoài ra, độ trễ ghi rõ ràng là cao hơn độ trễ đọc vì các thao các ghi luôn cần truy cập vào đĩa. Thêm nữa, độ trễ phân vị 99.9 là khoảng 200 ms và cao hơn mức trung bình khá nhiều. Điều này là do độ trễ phân vị 99.9 bị ảnh hưởng bởi nhiều yếu tố như biến động của tải request, kích thước object và mô hình truy cập cục bộ.
Mặc dù mức hiệu suất này có thể chấp nhận được với một số service, nhưng một số dịch vụ hướng tới khách hàng còn yêu cầu mức hiệu suất cao hơn. Với các service này, Dynamo cung cấp khả năng đánh đổi độ bền để lấy hiệu suất cao. Trong quá trình tối ưu hoá, mỗi node lưu trữ duy trì một object buffer trong bộ nhớ chính. Mỗi thao tác ghi được lưu vào buffer và được ghi định kỳ vào đĩa bởi một luồng ghi. Trong kế hoạch này, thao tác đọc sẽ kiểm tra xem key có nằm trong buffer không. Nếu có thì object được đọc từ buffer thay vì đọc từ engine lưu trữ.
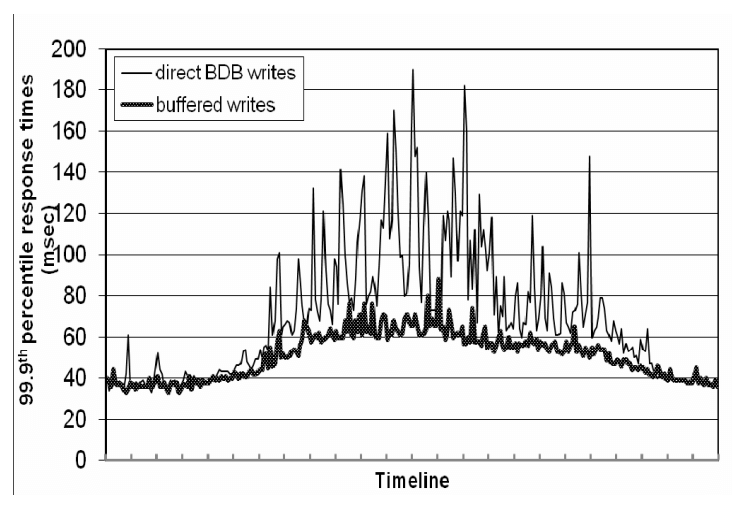
Tối ưu này khiến độ trễ phân vị 99.9 giảm đi 5 lần trong giờ cao điểm, ngay cả với một buffer rất nhỏ gồm 1000 object (xem hình 5). Ngoài ra, việc ghi vào buffer sẽ làm giảm độ trễ ở phân vị cao hơn. Rõ ràng, kế hoạch này đánh đổi độ bền để lấy hiệu suất. Trong kế hoạch này, server chết sẽ làm mất đi một số lần ghi trong buffer. Đẻ giảm rủi ro, thao tác ghi được tinh chỉnh lại để cho phép node điều phối chọn một trong N replica để thực hiện một "durable write". Vì node điều phối chỉ cần chờ W phản hồi, hiệu suất của thao tác ghi không bị ảnh hưởng bởi hiệu suất của thao tác durable write được thực hiện bởi một replica duy nhất.
6.2. Đảm bảo phân phối tải đều
Dynamo dùng consistent hashing để phân vùng không gian key của nó qua các replica và đảm bảo phân phối tải đều. Một phân phối key đều có thể giúp chúng ta đạt được phân phối tải đều, giả định rằng phân phối truy cập các key không bị lệch quá nhiều. Đặc biệt, thiết kế Dynamo giả định rằng ngay cả khi phân phối truy cập các key bị lệch, vẫn có đủ các key phổ biến để phân phối tải đều qua các node. Phần này sẽ thảo luận về sự mất cân bằng tải và ảnh hưởng của các chiến lược phân vùng khác nhau đến phân phối tải.
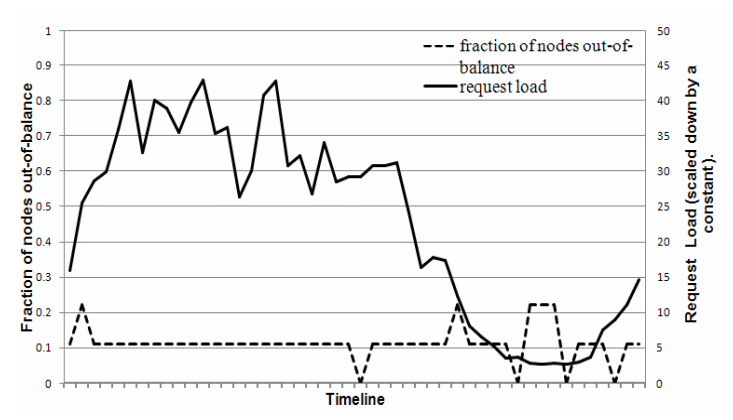
Để nghiên cứu sự mất cân bằng tải và sự tương quan của nó với số request, tổng số request nhận được bởi mỗi node được đo trong một khoảng thời gian 24 giờ - được chia thành các khoảng thời gian 30 phút. Trong khoảng thời gian này, một node được coi là "mất cân bằng tải" nếu tải của node lệch khỏi tải trung bình một giá trị nhỏ hơn một ngưỡng nhất định (ở đây là 15%). Nếu không thì node đó được gọi là "quá mất cân bằng tải". Hình 6 cho thấy tỉ lệ các node bị mất cân bằng tải trong khoảng thời gian đó. Như ta thấy, tỉ lệ các node bị mất cân bằng tải giảm khi tải tăng. Ví dụ, trong các khoảng thời gian có tải thấp, tỉ lệ các node bị mất cân bằng tải là 20% và trong các khoảng thời gian có tải cao, tỉ lệ này là 10%. Một cách giải thích cho hiện tượng này là do việc tải tăng dẫn đến việc truy cập các key phổ biến hơn, do đó phân phối tải đều hơn. Tuy nhiên, trong các khoảng thời gian có tải thấp, ít key phổ biến được truy cập, do đó phân phối tải không đều.
Phần này sẽ nói về cách sơ đồ phân vùng của Dynamo phát triển theo thời gian và ý nghĩa của nó với việc phân bố tải.
Chiến lược 1: T token ngẫu nhiên cho mỗi node và phân vùng theo giá trị token: Đây là chiến lược được triển khai ban đầu trong thực tế (được mô tả trong phần 4.2). Trong chiến lược này, mỗi node được gán T token (chọn ngẫu nhiên trong không gian hash). Các token của tất cả các node được sắp xếp theo giá trị của chúng theo không gian hash. Mỗi cặp token liên tiếp định nghĩa một đoạn. Token cuối cùng và token đầu tiên tạo thành một khoảng "bọc quanh" từ giá trị cao nhất đến giá trị thấp nhất trong không gian hash. Vì các token được chọn ngẫu nhiên, các đoạn có kích thước khác nhau. Khi các node tham gia và rời khỏi hệ thống, tập token thay đổi và do đó các đoạn cũng thay đổi. Lưu ý rằng không gian cần thiết để duy trì thành viên tại mỗi node tăng tuyến tính với số lượng node trong hệ thống.
Khi sử dụng chiến lược này, chúng tôi đã gặp những vấn đề sau. Thứ nhất, khi một node mới được thêm vào, nó cần phải lấy đoạn key từ các node khác. Tuy nhiên, các node chuyển các đoạn key cho node mới phải quét kho lưu trữ cục bộ của chúng để lấy được tập các data item thích hợp. Lưu ý rằng việc thực hiện thao tác quét như vậy trong thực tế rất phức tạp vì nó là hoạt động tiêu tốn tài nguyên và chúng cần được thực thi ở background để không ảnh hưởng đến hiệu suất của khách hàng. Điều này yêu cầu chúng tôi phải chạy các nhiệm vụ khởi động ở mức ưu tiên thấp nhất. Tuy nhiên, điều này làm chậm quá trình khởi động và trong mùa mua sắm bận rộn, khi các node xử lý hàng triệu request mỗi ngày, quá trình khởi động có thể mất gần một ngày để hoàn thành. Thứ hai, khi một node được thêm / xoá hệ thống, các đoạn key của nhiều node thay đổi và các cây Merkle cho các đoạn mới cần được tính toán lại. Tương tự, việc này cũng rất phức tạp và tốn thời gian. Cuối cùng, không có cách nào để tạo ra một bản chụp của toàn bộ không gian key vì sự ngẫu nhiên của các đoạn key, điều này làm cho việc lưu trữ lịch sử trở nên phức tạp. Trong chiến lược này, việc lưu trữ toàn bộ không gian key yêu cầu chúng tôi phải lấy các key từng node một, điều này rất kém hiệu quả.
Vấn đề cơ bản với chiến lượt này là các sơ đồ phân vùng dữ liệu và vị trí dữ liệu bị đan xen với nhau. Ví dụ, trong một số trường hợp, ta nên thêm nhiều node hơn vào hệ thống để xử lý tải tăng. Tuy nhiên, trong trường hiwpj này, không thể thêm node mà không ảnh hưởng đến việc phân vùng dữ liệu. Lý tưởng nhất là nên sử dụng các sơ đồ độc lập để phân vùng và sắp xếp. Để đạt được mục tiêu này, các chiến lược sau đây đã được đánh giá:
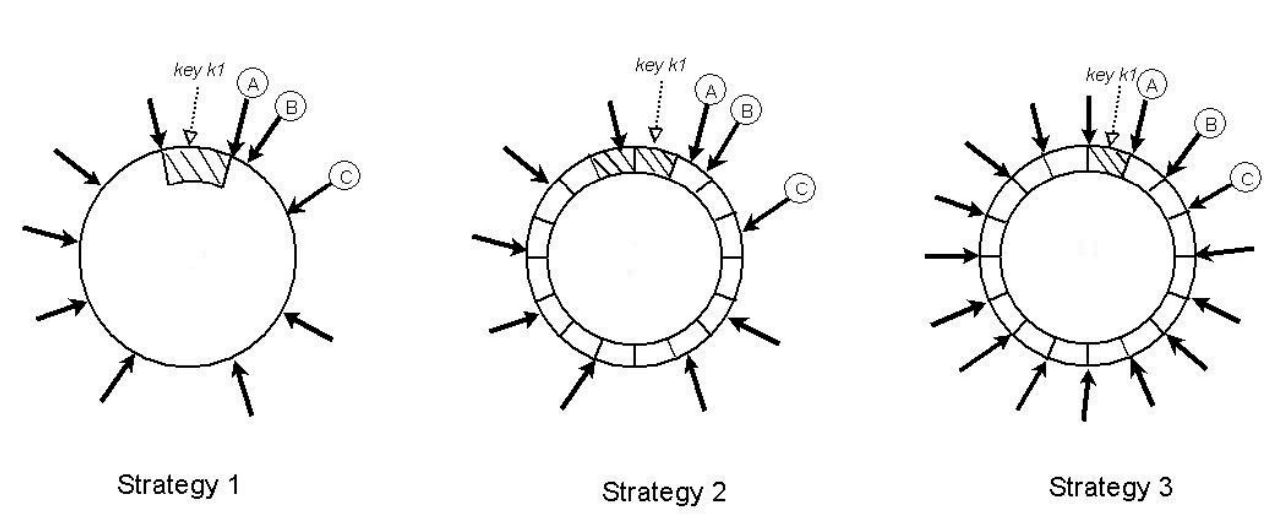
Chiến lược 2: T token ngẫu nhiên cho mỗi node và phân vùng các đoạn bằng nhau: Trong chiến lược này, không gian hash được chia thành Q đoạn bằng nhau và mỗi node có T token. Q thường được đặt sao cho Q >> N và Q >> S*T, trong đó S là số node trong hệ thống. Trong chiến lược này, các token được sử dụng để xây dựng hàm ánh xạ các giá trị trong không gian hash thành danh sách các node theo thứ tự và không dùng để phân vùng. Mỗi đoạn được đặt trên N node đầu tiên được tìm thấy khi đi theo vòng consistent hashing theo chiều kim đồng hồ từ cuối đoạn. Hình 7 minh họa chiến lược này cho N=3. Trong ví dụ này, các node A, B và C được tìm thấy khi đi theo vòng consistent hashing từ cuối đoạn chứa key k1. Lợi thế chính của chiến lược này là: (i) phân vùng và vị trí của các key được độc lập với nhau, (ii) khả năng thay đổi chiến lược phân vùng trong quá trình chạy.
Chiến lược 3: Q/S token cho mỗi node, phân vùng các đoạn bằng nhau: Tương tự chiến lược 2, chiến lược này chia không gian hash thành Q đoạn bằng nhau và việc đặt vị trí của đoạn sẽ độc lập với sơ đồ phân vùng. Hơn nữa, mỗi node được gán Q/S token, với S là số node trong hệ thống. Khi một node bị xoá, token của chúng được phân bố ngẫu nhiên đến các node còn lại sao cho các tính chất này được giữ nguyên. Tương tự, khi một node được thêm vào, nó lấy các token từ các node trong hệ thống theo cách giữ nguyên các tính chất vừa rồi.
Hiệu quả của 3 chiến lược này được đánh giá cho hệ thống với S=30 và N=3. Tuy nhiên, thật khó để so sánh các chiến lược khác nhau này một cách công bằng vì các chiến lược khác nhau có cấu hình khác nhau để điều chỉnh hiệu quả. Ví dụ, thuộc tính phân phối tải của chiến lược 1 phụ thuộc vào số token (tức là T), trong khi chiến lược 3 phụ thuộc vào số phân vùng (tức là Q). Một cách để so sánh các chiến lược này là đánh giá độ lệch trong phân bố tải của chúng trong khi tất cả các chiến lược đều sử dụng cùng một lượng không gian bộ nhớ để duy trì thông tin thành viên. Ví dụ, trong chiến lược 1, mỗi node cần duy trì vị trí token của tất cả các node trong vòng consistent hashing và trong chiến lược 3, mỗi node cần duy trì thông tin về các phân vùng được gán cho mỗi node.
Trong thí nghiệm tiếp theo, các chiến lược này được đánh giá bằng cách thay đổi các tham số liên quan (T và Q). Hiệu quả cân bằng tải của mỗi chiến lược được đo bằng cách thay đổi kích thước thông tin thành viên mà mỗi node cần duy trì, trong đó hiệu quả cân bằng tải được định nghĩa là tỉ lệ số request trung bình được thực hiện bởi mỗi node so với số request tối đa được thực hiện bởi node có tải cao nhất.
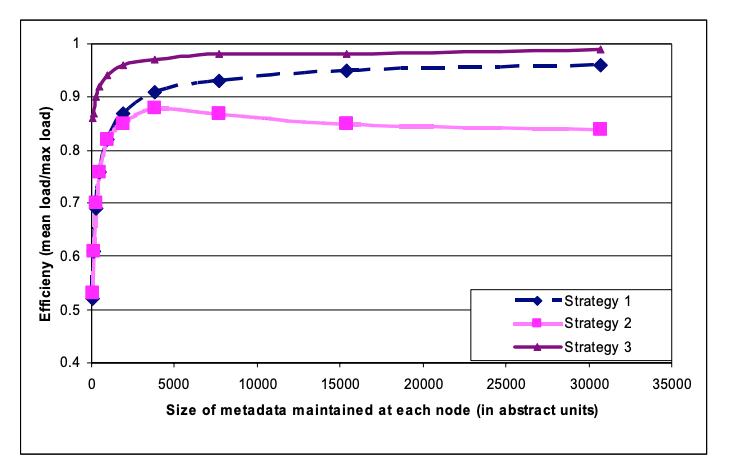
Kết quả nằm trong hình 8. Như ta thấy, chiến lược 3 đạt được hiệu quả cân bằng tải tốt nhất và chiến lược 2 có hiệu quả cân bằng tải kém nhất. Trong một thời gian ngắn, chiến lược 2 đóng vai trò thiết lập tạm thời trong quá trình di chuyển các instance từ chiến lược 1 sang chiến lược 3. So với chiến lược 1, chiến lược 3 đạt được hiệu quả tốt hơn và làm giảm đi 3 lần kích thước thông tin thành viên được duy trì ở mỗi node điều phối. Trong khi lưu trữ không phải là một vấn đề lớn, các node gossip thông tin thành viên định kỳ và do đó việc duy trì thông tin này càng nhỏ càng tốt. Ngoài ra, chiến lược 3 có những ưu điểm và dễ triển khai hơn vì: (i) khởi động / khôi phục nhanh hơn: Vì các đoạn được cố định, chúng có thể được lưu trữ trong các file riêng biệt, điều này làm cho việc khởi động và khôi phục dữ liệu đơn giản hơn. (ii) Dễ lưu trữ: Lưu trữ định kỳ của bộ dữ liệu là một yêu cầu bắt buộc cho hầu hết các dịch vụ lưu trữ của Amazon. Việc lưu trữ toàn bộ bộ dữ liệu được lưu trữ bởi Dynamo đơn giản hơn trong chiến lược 3 vì các file đoạn có thể được lưu trữ riêng biệt. Ngược lại, trong chiến lược 1, các token được chọn ngẫu nhiên và việc lưu trữ dữ liệu được lưu trữ bởi Dynamo yêu cầu phải lấy các key từng node một, điều này thường không hiệu quả và chậm chạp. Nhược điểm của chiến lược 3 là việc thay đổi thành viên của node điều phối yêu cầu phải đồng bộ hóa để đảm bảo các tính chất cần thiết của phân vùng.
6.3. Các version khác nhau: Khi nào và bao nhiêu?
Như đã nói ở trên, Dynamo được thiết kế để đánh đổi tính nhất quán để lấy tính khả dụng. Để hiểu tác động chính xác của các sự cố khác nhau đến tính nhất quán, cần có dữ liệu chi tiết về nhiều yếu tố: thời gian chết, loại sự cố, độ tin cậy của thành phần, khối lượng công việc, v.v. Việc trình bày các con số này chi tiết nằm ngoài phạm vi của bài báo này. Tuy nhiên, phần này sẽ thảo luận về một số chỉ số đáng nói: số lượng các version khác nhau trong môi trường thực tế.
Các version khác nhau của một data item phát sinh trong hai trường hợp. Trường hợp thứ nhất là khi hệ thống đang gặp các tình huống sự cố như sự cố node, sự cố trung tâm dữ liệu và phân vùng mạng. Trường hợp thứ hai là khi hệ thống đang xử lý một lượng lớn các writer đồng thời cho một data item duy nhất và nhiều node kết thúc việc đồng bộ hóa các bản cập nhật đồng thời. Từ cả hai khía cạnh về tính sử dụng và hiệu quả, cần giảm thiểu số lượng các version khác nhau trong bất kỳ thời điểm nào. Nếu các version không thể được đối chiếu cú pháp dựa trên vector clock, chúng phải được chuyển đến tầng ứng dụng để đối chiếu ngữ nghĩa. Đối chiếu ngữ nghĩa tăng tải lên các service, vì vậy cần giảm thiểu nhu cầu này.
Trong thí nghiệm tiếp theo, số lượng version được trả về dịch vụ giỏ hàng được đo trong một khoảng thời gian 24 giờ. Trong khoảng thời gian này, 99.94% các request chỉ nhận được một version; 0.00057% các request nhận được 2 version; 0.00047% các request nhận được 3 version và 0.00009% các request nhận được 4 version. Điều này cho thấy các version khác nhau hiếm khi được tạo ra.
Kinh nghiệm cho thấy rằng sự gia tăng số lượng các version khác nhau không phải do các sự cố mà do số lượng các writer đồng thời tăng lên. Sự gia tăng số lượng các version khác nhau thường do các robot (chương trình client tự động) gây ra và hiếm khi do con người gây ra. Vấn đề này không được thảo luận chi tiết do tính nhạy cảm của nó.
6.4. Phối hợp theo hướng client hay hướng server
Như đã nói ở phần 5, Dynamo có một thành phần điều phối request dùng máy trạng thái để xử lý các request. Client request thường được phân bố đều qua các node trên vòng với sự giúp sức của load balancer. Bất kỳ node Dynamo nào cũng có thể là điều phối cho một request đọc. Ngược lại, các request ghi sẽ được điều phối bởi một node trong danh sách ưu tiên hiện tại của key. Hạn chế này là do các node ưu tiên này có trách nhiệm thêm một version mới mà có thể gây ra sự thay đổi theo thứ tự của version đã được cập nhật bởi request ghi. Lưu ý rằng nếu sơ đồ version của Dynamo dựa trên timestamp, bất kỳ node nào cũng có thể điều phối một request ghi.
Một cách khác để điều phối request là chuyển máy trạng thái về các node client. Trong kế hoạch này, các ứng dụng client sử dụng một thư viện để thực hiện việc điều phối request tại các node client. Một client định kỳ chọn một node Dynamo ngẫu nhiên và tải về sơ đồ thành viên hiện tại của Dynamo. Sử dụng thông tin này, client có thể xác định tập các node tạo thành danh sách ưu tiên cho bất kỳ key nào. Các request đọc có thể được điều phối tại node client, do đó tránh được việc tăng thêm một bước truyền thông mạng nếu request được giao cho một node Dynamo ngẫu nhiên bởi load balancer. Các request ghi sẽ được chuyển tiếp đến một node trong danh sách ưu tiên của key hoặc chúng có thể được điều phối cục bộ nếu Dynamo sử dụng timestamp để tạo version.
Ưu điểm quan trọng của phương pháp điều phối hướng client là load balancer không còn cần thiết để phân phối tải client nữa. Việc phân phối tải hợp lý được đảm bảo hoàn toán bằng cách gán các key gần như thống nhất cho các node lưu trữ. Rõ ràng, hiệu quả của kế hoạch này phụ thuộc vào mức độ cập nhật thông tin thành viên tại client. Hiện tại, client định kỳ gửi một request tới một node Dynamo ngẫu nhiên mỗi 10 giây để cập nhật thông tin thành viên. Cách này được chọn thay vì cách push từ node vì nó mở rộng quy mô tốt hơn với số lượng client lớn và yêu cầu ít trạng thái được duy trì hơn tại server. Tuy nhiên, trong trường hợp xấu nhất, client có thể bị ảnh hưởng bởi thông tin thành viên bị cũ trong khoảng thời gian 10 giây. Trong trường hợp này, client sẽ cập nhật thông tin thành viên ngay lập tức nếu nó thấy thông tin bị cũ (ví dụ như khi có vài node bị chết)
| Độ trễ đọc phân vị 99.9 (ms) | Độ trễ ghi phân vị 99.9 (ms) | Độ trễ đọc trung bình (ms) | Độ trễ ghi trung bình (ms) |
|---|---|---|---|
| Hướng server | 68.9 | 68.5 | 3.9 |
| Hướng client | 30.4 | 30.4 | 1.55 |
Bảng 2 ở trên cho thấy sự cải thiện về độ trễ ở phân vị 99.9 và trung bình được theo dõi trong khoảng thời gian 24 tiếng với cách điều phối hướng client so với hướng server. Như ta thấy, cách tiếp cận điều phối hướng client giảm độ trễ ít nhất 30 ms cho phân vị 99.9 và giảm độ trễ trung bình đi 3 đến 4 ms. Sự cải thiện về độ trễ là do cách tiếp cận điều phối hướng client loại bỏ được các chi phí của load balancer và các bước truyền thông mạng thêm vào khi một request được giao cho một node ngẫu nhiên. Như ta thấy trong bảng, độ trễ trung bình thường thấp hơn độ trễ ở phân vị 99.9. Điều này là do bộ nhớ đệm và bộ đệm ghi của hệ thống Dynamo có tỷ lệ trúng cao. Hơn nữa, vì load balancer và mạng tăng biến động vào thời gian phản hồi, sự cải thiện về thời gian phản hồi ở phân vị 99.9 so với trung bình là cao hơn.
6.5. Cân bằng tác vụ background và foreground
Mỗi node thực hiện các loại tác vụ background khác nhau để đồng bộ hoá replica và data handoff (do hinting hoặc do thêm / xoá node) ngoài các hoạt động foreground get/put bình thường. Ban đầu, các tác vụ background này gây ra vấn đề tranh chấp tài nguyên và ảnh hưởng đến hiệu suất của các thao tác get/put. Do đó, cần phải đảm bảo rằng các tác vụ background chỉ được chạy khi các thao tác quan trọng thông thường không bị ảnh hưởng đáng kể. Để đạt được điều này, các tác vụ background được tích hợp với cơ chế kiểm soát tiếp nhận. Mỗi tác vụ background sử dụng nó để dự trữ các phần tài nguyên (như database), được chia sẻ trên tất cả các tác vụ background. Một cơ chế phản hồi dựa trên hiệu suất được sử dụng để thay đổi số lượng phần được cấp cho các tác vụ background.
Bộ điều khiển tiếp nhận liên tục giám sát hành vi truy cập tài nguyên trong khi thực hiện thao tác foreground get/put. Các khía cạnh được giám sát bao gồm thời gian truy cập đĩa, các truy cập database bị lỗi do tranh chấp khóa và hết thời gian giao dịch, thời gian chờ hàng đợi yêu cầu, v.v. Thông tin này được sử dụng để kiểm tra xem phần trăm độ trễ (hoặc lỗi) trong khoảng thời gian kéo dài nhất định có gần với ngưỡng mong muốn hay không. Ví dụ, bộ điều khiển tiếp nhận kiểm tra xem phân vị 99 của thời gian truy cập đĩa (trong 60 giây gần đây) có gần với ngưỡng 50 ms hay không. Bộ điều khiển sử dụng các so sánh này để đánh giá sự khả dụng của tài nguyên cho các thao tác foreground. Sau đó, nó quyết định số lượng phần tài nguyên được cấp cho các tác vụ background. từ đó sử dụng vòng phản hồi để hạn chế sự xâm nhập của các tác vụ background. Lưu ý rằng một vấn đề tương tự đã được nghiên cứu trong [4] để quản lý các tác vụ background.
6.6. Thảo luận
Phần này tổng hợp một số kinh nghiệm thu được trong quá trình triển khai và bảo trì Dynamo. Nhiều dịch vụ nội bộ của Amazon đã sử dụng Dynamo trong hai năm qua và nó đã cung cấp mức độ khả dụng đáng kể cho các ứng dụng của nó. Đặc biệt, các ứng dụng đã nhận được các phản hồi thành công (không bị hết thời gian) cho 99.9995% các request và không có chuyện mất dữ liệu nào xảy ra.
Hơn nữa, ưu điểm chính của Dynamo là nó cung cấp cấu hình cần thiết với 3 tham số (N, R, W) để điều chỉnh instance dựa trên như cầu. Không như các data store phổ biến, Dynamo tiết lộ các vấn đề về nhất quán dữ liệu và logic đối chiếu cho các nhà phát triển. Lúc đầu, người ta có thể nghĩ logic ứng dụng sẽ trở nên phức tạp hơn. Tuy nhiên, nền tảng Amazon được thiết kế để có tính khả dụng cao và nhiều ứng dụng được thiết kế để xử lý nhiều kiểu sự cố và sự không nhất quán có thể xảy ra. Do đó, việc chuyển các ứng dụng như vậy để dùng Dynamo là một việc tương đối đơn giản. Với các ứng dụng mới muốn dùng Dynamo, cần phải thực hiện một số phân tích trong giai đoạn phát triển ban đầu để chọn cơ chế giải quyết xung đột phù hợp, đáp ứng use case một cách thích hợp. Cuối cùng, Dynamo áp dụng mô hình thành viên trong đó mỗi node nhận biết dữ liệu được lưu trữ bởi các peer của nó. Để làm được điều này, mỗi node thường xuyên gossip bảng định tuyến đầy đủ với các node khác trong hệ thống. Mô hình này hoạt động tốt cho một hệ thống chứa vài trăm node. Tuy nhiên, việc mở rộng thiết kế này để chạy với hàng ngàn node không đơn giản vì chi phí duy trì bảng định tuyến tăng theo kích thước hệ thống. Vấn đề này có thể được khắc phục bằng cách giới thiệu các phần mở rộng phân cấp cho Dynamo. Ngoài ra, lưu ý rằng vấn đề này đang được giải quyết tích cực bởi các hệ thống DHT O(1) (ví dụ như [14]).
7. Kết luận
Bài báo này mô tả Dynamo, một data store có tính khả dụng và tính mở rộng cao, được dùng để lưu trạng thái của nhiều service cốt lõi của nền tảng thương mại điện tử Amazon.com. Dynamo cung cấp một mức độ khả dụng và hiệu suất mong muốn và đã thành công trong việc xử lý lỗi của các server, các trung tâm dữ liệu và phân vùng mạng. Dynamo có thể mở rộng quy mô và cho phép người quản trị service mở rộng hay thu hẹp quy mô dựa trên nhu cầu. Dynamo cho phép người quản trị tùy chỉnh hệ thống lưu trữ đáp ứng các yêu cầu về hiệu suất, tính bền vững và nhất quán thông qua SLA bằng cách cho phép chúng điều chỉnh các tham số N, R và W.
Việc sử dụng Dynamo trong thực tế những năm qua chứng tỏ rằng các kỹ thuật phi tập trung có thể được kết hợp để tạo ra một hệ thống duy nhất có tính khả dụng cao. Thành công của nó trong một trong những môi trường ứng dụng khắc nghiệt nhất cho thấy rằng một hệ thống lưu trữ eventual-consistent có thể là một phần quan trọng cho các ứng dụng có tính khả dụng cao.
Lời cảm ơn
Các tác giả xin cảm ơn Pat Helland vì những đóng góp của ông cho thiết kế ban đầu của Dynamo. Chúng tôi cũng xin cảm ơn những nhận xét của Marvin Theimer và Robert van Renesse. Cuối cùng, chúng tôi muốn cảm ơn người hướng dẫn của chúng tôi, Jeff Mogul, vì những nhận xét và thông tin đầu vào chi tiết của anh ấy trong khi chuẩn bị bản cuối của bài báo này, giúp cải thiện đáng kể chất lượng của bài.
Tham khảo
[1] Adya, A., Bolosky, W. J., Castro, M., Cermak, G., Chaiken, R., Douceur, J. R., Howell, J., Lorch, J. R., Theimer, M., and Wattenhofer, R. P. 2002. Farsite: federated, available, and reliable storage for an incompletely trusted environment. SIGOPS Oper. Syst. Rev. 36, SI (Dec. 2002), 1-14.
[2] Bernstein, P.A., and Goodman, N. An algorithm for concurrency control and recovery in replicated distributed databases. ACM Trans. on Database Systems, 9(4):596-615, December 1984
[3] Chang, F., Dean, J., Ghemawat, S., Hsieh, W. C., Wallach, D. A., Burrows, M., Chandra, T., Fikes, A., and Gruber, R. E. 2006. Bigtable: a distributed storage system for structured data. In Proceedings of the 7th Conference on USENIX Symposium on Operating Systems Design and Implementation - Volume 7 (Seattle, WA, November 06 - 08, 2006). USENIX Association, Berkeley, CA, 15-15.
[4] Douceur, J. R. and Bolosky, W. J. 2000. Process-based regulation of low-importance processes. SIGOPS Oper. Syst. Rev. 34, 2 (Apr. 2000), 26-27.
[5] Fox, A., Gribble, S. D., Chawathe, Y., Brewer, E. A., and Gauthier, P. 1997. Cluster-based scalable network services. In Proceedings of the Sixteenth ACM Symposium on Operating Systems Principles (Saint Malo, France, October 05 - 08, 1997). W. M. Waite, Ed. SOSP '97. ACM Press, New York, NY, 78-91.
[6] Ghemawat, S., Gobioff, H., and Leung, S. 2003. The Google file system. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles (Bolton Landing, NY, USA, October 19 - 22, 2003). SOSP '03. ACM Press, New York, NY, 29-43.
[7] Gray, J., Helland, P., O'Neil, P., and Shasha, D. 1996. The dangers of replication and a solution. In Proceedings of the 1996 ACM SIGMOD international Conference on Management of Data (Montreal, Quebec, Canada, June 04 - 06, 1996). J. Widom, Ed. SIGMOD '96. ACM Press, New York, NY, 173-182.
[8] Gupta, I., Chandra, T. D., and Goldszmidt, G. S. 2001. On scalable and efficient distributed failure detectors. In Proceedings of the Twentieth Annual ACM Symposium on Principles of Distributed Computing (Newport, Rhode Island, United States). PODC '01. ACM Press, New York, NY, 170-179.
[9] Kubiatowicz, J., Bindel, D., Chen, Y., Czerwinski, S., Eaton, P., Geels, D., Gummadi, R., Rhea, S., Weatherspoon, H., Wells, C., and Zhao, B. 2000. OceanStore: an architecture for global-scale persistent storage. SIGARCH Comput. Archit. News 28, 5 (Dec. 2000), 190-201.
[10] Karger, D., Lehman, E., Leighton, T., Panigrahy, R., Levine, M., and Lewin, D. 1997. Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web. In Proceedings of the Twenty-Ninth Annual ACM Symposium on theory of Computing (El Paso, Texas, United States, May 04 - 06, 1997). STOC '97. ACM Press, New York, NY, 654-663.
[11] Lindsay, B.G., et. al., “Notes on Distributed Databases”, Research Report RJ2571(33471), IBM Research, July 1979
[12] Lamport, L. Time, clocks, and the ordering of events in a distributed system. ACM Communications, 21(7), pp. 558-565, 1978.
[13] Merkle, R. A digital signature based on a conventional encryption function. Proceedings of CRYPTO, pages 369–378. Springer-Verlag, 1988.
[14] Ramasubramanian, V., and Sirer, E. G. Beehive: O(1) lookup performance for power-law query distributions in peer-topeer overlays. In Proceedings of the 1st Conference on Symposium on Networked Systems Design and Implementation, San Francisco, CA, March 29 - 31, 2004.
[15] Reiher, P., Heidemann, J., Ratner, D., Skinner, G., and Popek, G. 1994. Resolving file conflicts in the Ficus file system. In Proceedings of the USENIX Summer 1994 Technical Conference on USENIX Summer 1994 Technical Conference - Volume 1 (Boston, Massachusetts, June 06 - 10, 1994). USENIX Association, Berkeley, CA, 12-12.
[16] Rowstron, A., and Druschel, P. Pastry: Scalable, decentralized object location and routing for large-scale peerto-peer systems. Proceedings of Middleware, pages 329-350, November, 2001.
[17] Rowstron, A., and Druschel, P. Storage management and caching in PAST, a large-scale, persistent peer-to-peer storage utility. Proceedings of Symposium on Operating Systems Principles, October 2001.
[18] Saito, Y., Frølund, S., Veitch, A., Merchant, A., and Spence, S. 2004. FAB: building distributed enterprise disk arrays from commodity components. SIGOPS Oper. Syst. Rev. 38, 5 (Dec. 2004), 48-58.
[19] Satyanarayanan, M., Kistler, J.J., Siegel, E.H. Coda: A Resilient Distributed File System. IEEE Workshop on Workstation Operating Systems, Nov. 1987.
[20] Stoica, I., Morris, R., Karger, D., Kaashoek, M. F., and Balakrishnan, H. 2001. Chord: A scalable peer-to-peer lookup service for internet applications. In Proceedings of the 2001 Conference on Applications, Technologies, Architectures, and Protocols For Computer Communications (San Diego, California, United States). SIGCOMM '01. ACM Press, New York, NY, 149-160.
[21] Terry, D. B., Theimer, M. M., Petersen, K., Demers, A. J., Spreitzer, M. J., and Hauser, C. H. 1995. Managing update conflicts in Bayou, a weakly connected replicated storage system. In Proceedings of the Fifteenth ACM Symposium on Operating Systems Principles (Copper Mountain, Colorado, United States, December 03 - 06, 1995). M. B. Jones, Ed. SOSP '95. ACM Press, New York, NY, 172-182.
[22] Thomas, R. H. A majority consensus approach to concurrency control for multiple copy databases. ACM Transactions on Database Systems 4 (2): 180-209, 1979.
[23] Weatherspoon, H., Eaton, P., Chun, B., and Kubiatowicz, J. 2007. Antiquity: exploiting a secure log for wide-area distributed storage. SIGOPS Oper. Syst. Rev. 41, 3 (Jun. 2007), 371-384.
[24] Welsh, M., Culler, D., and Brewer, E. 2001. SEDA: an architecture for well-conditioned, scalable internet services. In Proceedings of the Eighteenth ACM Symposium on Operating Systems Principles (Banff, Alberta, Canada, October 21 - 24, 2001). SOSP '01. ACM Press, New York, NY, 230-243.